

PostgreSQL Interview Questions and Answers 2023

PostgreSQL is a really powerful, open-source, object-relational database system which is known for its performance, scalability, reliability, and stability features. It was founded 30 years back, is ACID-compliant, and runs on all major operating systems. It has a huge community and is widely adopted in the software industry. It has emerged as a desirable software career option because of its advantages and acceptance in the software world. Below are the PostgreSQL interview questions divided into 3 sections:
Basic PostgreSQL Interview Questions
- What are the features of PostgreSQL?
- What are the advantages and disadvantages of PostgreSQL as a database?
- What is the difference between PostgreSQL and Redis?
- What are the advantages of PostgreSQL over MySQL?
- What makes PostgreSQL better than SQL Server?
- What are the few key reasons that lead more companies to switch to PostgreSQL?
- What are views in PostgreSQL?
- Is PostgreSQL a good option for big data?
Intermediate PostgreSQL Interview Questions
- How to effectively dump PostgreSQL databases?
- How to insert data into a PostgreSQL database?
- How to scale a huge PostgreSQL database?
- How to update multiple rows from a select query in PostgreSQL?
Advanced PostgreSQL Interview Questions
Basic PostgreSQL Interview Questions and Answers
1. What are the features of PostgreSQL?
Compatibility: PostgreSQL is compatible with all major operating systems such as - Windows, Linux, macOS, UNIX, etc. It supports various programming languages like - Python, Java, C, Ruby, Perl, etc.
Data integrity: Supports data integrity of the database by primary keys, unique keys, foreign keys, explicit locks, constraints, etc.
Data types: It supports a wide range of data types.
- Primitive: String, Integer, etc.
- Structured: Array, List, etc.
- Geometrical: Circle, Point, etc.
- Document: XML, JSON etc.
- Customised: User-defined, Composite, etc.
Extensible: Supports multiple procedural languages, foreign data wrappers, stored functions, customisable tables. It provides support to add external extensions to enhance the functionality and therefore it is highly extensible.
Secure: It provides a high standard of security through authentication protocols like LDAP(Lightweight Directory Access Protocol) and SSPI(Security Support Provider Interface). It has a powerful access control system to control the security of the database.
Reliable: It is highly dependable because it supports replications of the database- synchronous, asynchronous, and logical. Other security features are PITR(Point in time recovery), WAL(Write-ahead logging), etc.

2. What are the advantages and disadvantages of PostgreSQL as a database?
Advantages:
- Open-source provides free access to users for implementing and modifying it as per their need.
- High-risk tolerant database due to WAl and PITR implementations.
- Easy to learn and use.
- Supports dynamic web applications.
- Supports processing of complex data types like graphical data, geographical data, etc.
- User-defined data types, functions, triggers can be created.
Disadvantages:
- Performance is slower when compared to MySQL.
- The creation of database replication is a little complex.
- It is not maintained by a single company hence it is less popular.
3. What is the difference between PostgreSQL and Redis?
| PostgreSQL | Redis |
| It is an object-relational DBMS. | Key-value data store and not a DBMS. |
| Supports SQL triggers and foreign keys. | Does not support triggers and foreign keys. |
| Works on data schema. | It is schema-free. |
| It is more reliable than Redis. | It is faster than PostgreSQL. |
| Strong access control mechanism. | Simple password-based access control mechanism. |
4. What are the advantages of PostgreSQL over MySQL?
| PostgreSQL | MySQL |
| It is an object-relational database system, which supports table inheritance, method overloading, etc. | It is a relational database hence doesn't support these features. |
| It is fully ACID properties compliant. | ACID-compliant only when used with InnoDB and NDB Cluster Storage engines. |
| Provides MVCC(Multiversion Concurrency Control), hence reading never locks writing transactions and vice-versa. | Doesn’t provide MVCC, works on locks for concurrency control. |
| Supports complex data storage like- geometrical, JSON, XML, etc. | Lacks such wide support for data storage. |
| Customisation of data tables, functions, and triggers is supported. | Customisation is not available.
|
| Provides synchronous (2-safe) replication of the database. | Provides one-way synchronous replication of the database. |
5. What makes PostgreSQL better than SQL Server?
| PostgreSQL | SQL Server |
| Supports a wider range of Operating Systems- Windows, Unix, Solaris, FreeBSD, Linux, HP-UX, etc. | Supports limited Operating Systems- Windows, Linux, etc. |
| It has an advanced concurrency maintenance system. | It has a locking process as part of the concurrency management system, which causes deadlocks. |
| The compression process is free and automatic, hence provides better scalability. | The compression process is manual and hence it makes SQL Server less scalable as compared to PostgreSQL. |
| Dynamic actions can be performed easily through ‘SELECT’ statements. | Dynamic actions are not directly supported. |
| Supports CSV format, export, and import of data are supported. | Does not support CSV format, export, and import of data. |
| Supports the use of regular expressions(regex) for analytical tasks. | Doesn’t provide much support for regular expressions. |
6. What are the few key reasons that lead more companies to switch to PostgreSQL?
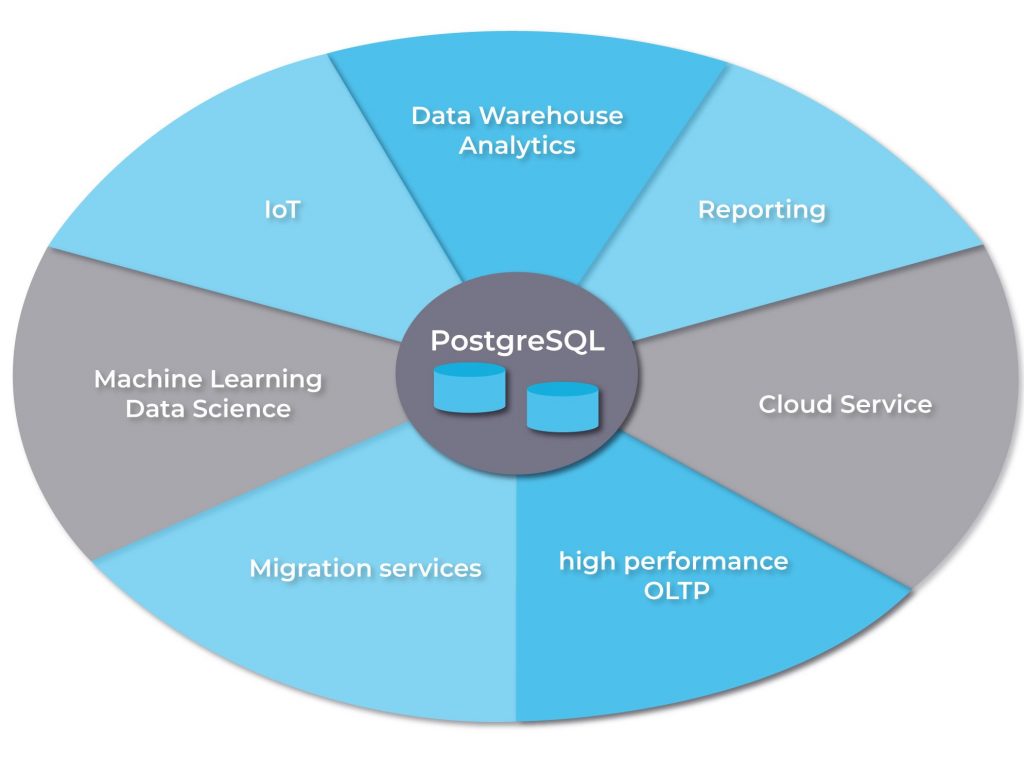
- It is open-source, hence this means no additional cost incurred in the usage.
- Helps companies in achieving high-level technology advancement through IoT, machine learning, cloud services, data warehouse analytics, etc.
- Highly reliable, secure, scalable, and stable.
- Strong community support, hence bugs are fixed faster.
7. What are views in PostgreSQL?
Views are virtual tables, which are a subset of data from the original table, provided according to the query. Often, views are used for showing specific data to the users who do not require to access the full table. Views can also summarize data from multiple tables to help in the reporting.
Example: Below is a table called ‘COMPANY’:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | Singapore | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000
We will create a view for the above table showing information from id, name, and age columns.
testdb=# CREATE VIEW COMPANY_VIEW AS SELECT ID, NAME, AGE FROM COMPANY;
Now the view can be queried in the same manner as we do with a table.
testdb=# SELECT * FROM COMPANY_VIEW;
This would produce the following result:
id | name | age ----+-------+----- 1 | Paul | 32 2 | Allen | 25 3 | Teddy | 23 4 | Mark | 25 5 | David | 27 6 | Kim | 22 7 | James | 24 (7 rows)
8. Is PostgreSQL a good option for big data?
Yes, is it a good option for big data due to the below reasons:
- In-built date and time functions.
- Supports unstructured data like JSON, XML, etc.
- Window functions for calculating averages and cumulative sums
- Provides statistical functions like- least square deviation, standard deviation, etc.
- Support for custom-made functions is available.
- Support for data cleaning is available.
- Supports parallel run of data queries.
- Declarative partitioning can be performed on the database, which helps in working on huge datasets distributed across the globe.

Intermediate PostgreSQL Interview Questions and Answers
9. How to effectively dump PostgreSQL databases?
We can dump a PostgreSQL database using any of the below tools:
- pg_dumpall: Dumps all the databases present in the PostgreSQL cluster to a plain text file. Through this command, we can dump tablespaces and roles, etc. which is not possible through pg_dump.
- pg_dump: Dumps databases one by one, unlike pg_dumpall. It can dump in four formats- plain, custom, tar, directory.
10. How to insert data into a PostgreSQL database?
The ‘INSERT’ command is used to insert data into a PostgreSQL database.
Syntax 1: INSERT INTO table_name(column1, column2, …) VALUES (value1, value2, …);
This command inserts values ‘value1’, ‘value2’ etc. in the columns ‘column1’, column2’ etc. of the table ‘table_name”.
INSERT INTO links (url, name, last_update)
VALUES('https://www.hackertrail.com','HackerTrail','2021-06-01');
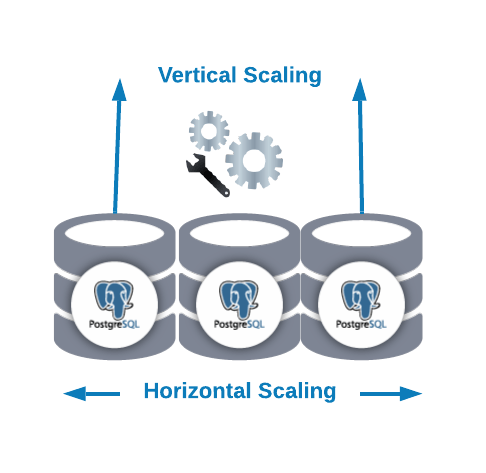
11. How to scale a huge PostgreSQL database?
Scalability is an important feature of PostgreSQL databases, which means that when the business expands, the database has the ability to expand and maintain good performance.
PostgreSQL achieves this by:
- Executing parallel queries on multiple CPU cores.
- All available memory can be used for caching via scaling.
- Multiple memory disks can be used with the help of partitioning.
There are two ways to scale a PostgreSQL database:
- Vertical scaling (scale-up): Hardware resources like memory, CPU, etc. are added to the database for scaling.
- Horizontal scaling (scale-out): Database nodes are added as slaves, to increase the size of the database cluster.
12. How to update multiple rows from a select query in PostgreSQL?
It can be done using the UPDATE query as below:
UPDATE table_name SET column_name=value, column_name_2=value_2 WHERE table_name.id in (SELECT id from other_table where <condition>)
Advanced PostgreSQL Interview Questions and Answers
13. How security is maintained in PostgreSQL databases?
Below practices may ensure security in the PostgreSQL database:
Avoid using Trust security:
A non-trust authentication method is more secure than Trust security authentication. Because Trust security enables anyone who is connected to the database, to access the data, which we do not want. An example of a non-trust authentication method is MD5, which can be used to provide better security in Postgresql.
Configuration of secure connections over SSL:
This is achieved by specifying the entries in pg_hba.conf file, by mentioning which hosts can use SSL-encrypted and unencrypted connections.
Tracking and logging queries:
We can install pg_stat_statements extension, to create a logging trail for all the queries executed.
Restricted port-level access to the database:
Only necessary ports should have access to the database such as - management ports and the database port itself.
Create secure groups and users for each application:
To provide access to the Postgre database create separate groups/users with appropriate access permissions for every new application.
Disable remote connections:
We can disable the remote connections by making an entry in pg_hba.conf. We can allow remote connections by using secure SSH.
Reject connection requests from unnecessary networks:
We can set ‘listen_addresses’ value to ‘localhost’ so that the operating system rejects connection requests from other servers.
Choose encryption methods wisely:
MD5 is a hash-based, one-way encryption method, which means it cannot be decrypted, and hence it is best to use such encryption methods for checking passwords.
14. How can we store binary data in PostgreSQL?
We can store the binary data in PostgreSQL by using the binary data types called ‘bytea’ which allows storage of binary strings.
Another method is by using the large object feature called OID. It stores the binary data in a separate table using a special format.
Below is the comparison table of two.
|
Characteristic |
BYTEA |
OID |
|
Max. allowed space |
1 GB |
2 GB |
|
Data access |
As a whole |
Stream-style |
|
Storage |
In defined table |
In pg_largeobject system table |
|
Data manipulation |
Using SQL and escaping sequnces |
Only within transaction block by special functions |
|
Loading |
Preload |
On demand |
Backend Technology Interview Questions
C Programming Language Interview Questions | PHP Interview Questions | .NET Core Interview Questions | NumPy Interview Questions | API Interview Questions | FastAPI Python Web Framework | Java Exception Handling Interview Questions | OOPs Interview Questions and Answers | Java Collections Interview Questions | System Design Interview Questions | Data Structure Concepts | Node.js Interview Questions | Django Interview Questions | React Interview Questions | Microservices Interview Questions | Key Backend Development Skills | Data Science Interview Questions | Python Interview Questions | Java Spring Framework Interview Questions | Spring Boot Interview Questions.
Frontend Technology Interview Questions
HTML Interview Questions | Angular Interview Questions | JavaScript Interview Questions | CSS Interview Questions
Database Interview Questions
SQL Interview Questions | MongoDB Interview Questions | MySQL Interview Questions | DBMS Interview Questions
Cloud Interview Questions
AWS Lambda Interview Questions | Azure Interview Questions | Cloud Computing Interview Questions | AWS Interview Questions
Quality Assurance Interview Questions
Moving from Manual Testing to Automated Testing | Selenium Interview Questions | Automation Testing Interview Questions
DevOps and Cyber Security Interview Questions
DevOps Interview Questions | How to Prevent Cyber Security Attacks | Guide to Ethical Hacking | Network Security Interview Questions
Design Product Interview Questions
Product Manager Interview Questions | UX Designer Interview Questions
Interview Preparation Tips
Strength and Weakness Interview Questions | I Accepted a Job Offer But Got Another Interview | Preparation Tips For the Virtual Technical Interview | 7 Tips to Improve Your GitHub Profile to Land a Job | Software Engineer Career Opportunities in Singapore | What can you expect during a whiteboard interview | How To Write A Resignation Letter | Recommendation Letter Templates and Tips.
Quick Links
Practice Skills | Best Tech Recruitment Agency in Singapore, India | Graduate Hiring | HackerTrail Litmus | Scout - Sourcing Top Tech Talent in ONE Minute | About HackerTrail | Careers | Job Openings.


