

Must Know Concepts on Data Structure

Data structures and algorithms
A data structure as the name indicates is a way to organise and manage data. Different data structures store the data in distinct ways, and there are specific methods to fetch the data from them. Therefore, the choice of data structures and algorithms depends on the task we want to perform.
Benefits of data structure:
- Easy and efficient storage, retrieval, and processing of data.
- By choosing an appropriate data structure, considerable processing time can be saved.
- They provide avenues to manage huge amounts of data efficiently.
- They are industry standards and have been used for years, therefore, their efficiency is well known.
- Data structures and algorithms help us in many real-life problems like- sorting, searching, LIFO, FIFO, etc.
Types of data structures: implementation and common operations
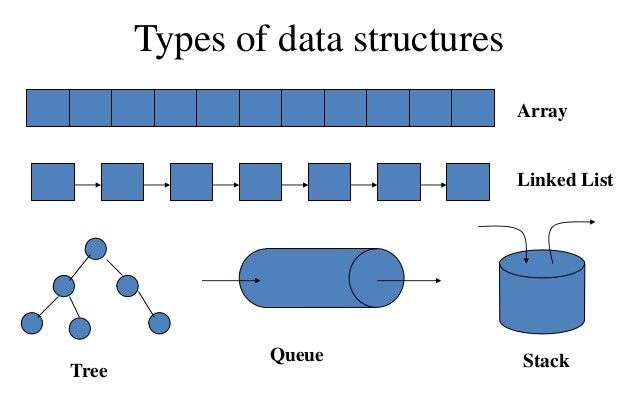
Array
They are of fixed size and hold the elements of the same data type. There are two attributes related to an array:
- Element: The data item which is stored in an array.
- Index: Data elements are stored at locations called index.
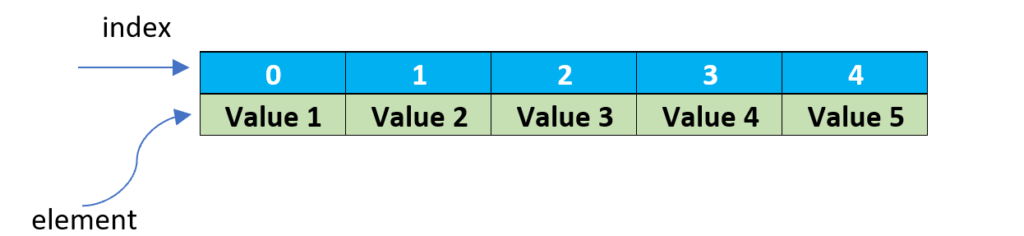
- The index starts with zero (0).
- In the above example of an array, there are five values stored in the array, starting from index (0) as Value 1 , Value 2, and so forth. Hence, the last value will be stored at index(4) and the size of this array is 5.
- For retrieving any element we use the index of the array. Example: Element at index 2, array[2] is ‘Value 3’
Operations on arrays:
- Insert: Inserts an element at the specified index.
- Delete: Deletes an element from the specified index.
- Traverse: Visits each element of the array one by one.
- Search: Searches for the required element in the array.
Commonly asked interview questions on arrays:
- Can we change the size of an array during runtime?
- Write an algorithm/program to find the second minimum element in the array.
- Can we provide the size of the array as a negative number?
Linked List
It is a data structure which is stored as a sequence of nodes. Each node has two attributes:
- Data element
- Link to the next node

- The ‘Head’ pointer stores the address of the first node.
- The last node stores ‘Null’ in the address of the next node.
- Each node has data and a link(address) to the next node.
- It has a dynamic size, unlike arrays.
- Insertion and deletion are easy.
Operations on the linked list:
- Insert: It inserts an element at the beginning of the list.
- Delete: It deletes elements at the beginning of the list.
- Search: Searches a data element in the linked list.
- Traverse: Visits the linked list nodes, one by one.
Commonly asked interview questions on the linked list:
- Where are linked lists used in programs?
- Which type of linked list is easy for traversing?
- How to delete the first node from a singly linked list?
Stack
It is a linear data structure, where the data operations can be performed only at one end i.e. top. Therefore, there is only one pointer which always points to the top of the stack.
Stack is also known as LIFO(Last in first out) data structure, because the element added last will be at the top. Hence, while fetching, the top element will be removed first.

- The size of the above stack is 5 since it can store five data elements.
- The first element pushed on the stack is 1, then 2,3, and so on. Element 1 was pushed first and is at the bottom of the stack.
- Last element 5 is pushed last and is on the top of the stack.
- While removal, the last pushed element will be fetched first, hence it is a LIFO.
Operations on stack:
- Push: Element is inserted into the stack using the operation push.
- Pop: Element is removed/fetched from the stack using the operation pop.
- Top: Returns the top element removing it from the stack.
Commonly asked interview questions on stack:
- When to use stack instead of arrays?
- How to reverse a stack without using any other data structure?
- Write an algorithm to check the parentheses are balanced in an expression, using stack.
Queue
It is similar to stack, the only difference is that the operations can happen from both ends of a queue. One end (front), is used to remove the elements, and the other end(rear), is used to add the elements. Therefore, a queue is a FIFO(First-in-first-out) data structure, the element inserted first will be removed first.
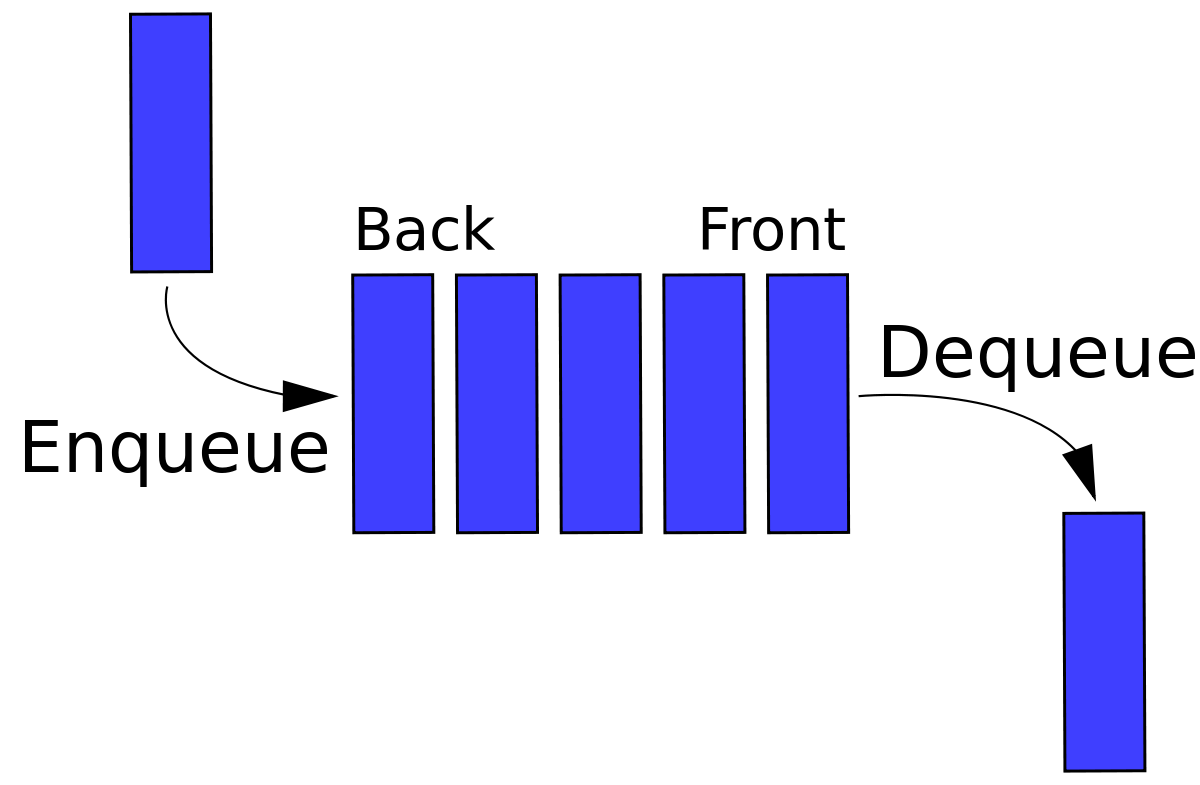
- The new element number 2 is being added at the rear of the queue.
- Number 5 is present at the front of the queue since it was added first.
- While removal, number 5 will be removed first from the queue and number 2 will be removed at the last.
Operations on queue:
- Enqueue: Adds/inserts a new element at the rear of the queue.
- Dequeue: Removes an element from the front of the queue.
Commonly asked interview questions on queue:
- What are priority queues?
- Why should we not implement a queue in an array data structure?
- What is a circular queue?
Graph
It is a non-linear data structure, which is composed of two attributes:
- Nodes(vertices): Represent the data stored in the graph.
- Edges(arc): Represents the relationship between the nodes.
Therefore, a graph is a set of vertices and edges as shown below:
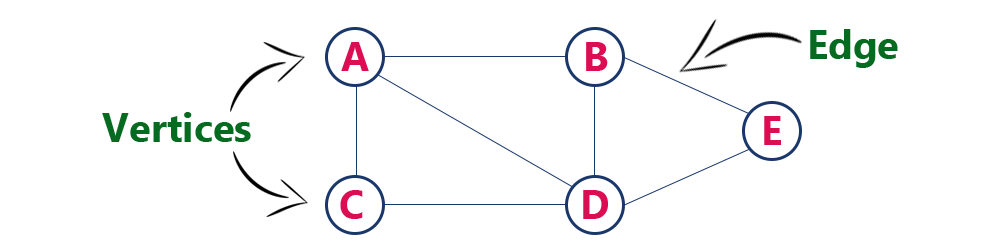
- The nodes/vertices A and C are connected through an edge.
- This edge represents a relationship between A and C, it is represented by a set (A, C).
- A graph can be directed or undirected. The above graph shows an undirected graph since no direction is mentioned.
Commonly asked interview questions on the graph:
- Write an algorithm to find the shortest path between two vertices.
- What are DFS(depth-first search) and BFS(breadth-first search) algorithms?
- Where should we use the Dijkstra algorithm?
Tree
It represents hierarchical data, in the form of nodes and edges. It is similar to a graph, the only difference is that it does not contain a loop/cycle of edges. There are multiple levels in a tree, which represent the hierarchy of the data.
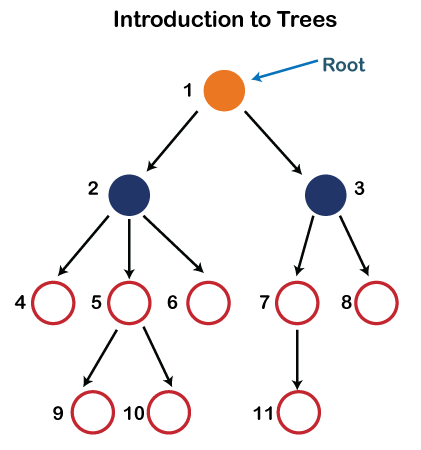
- Root: Node 1 is the root of the tree, which does not have any parent.
- Parent: Node 2 is the parent of nodes 4,5, and 6.
- Children: Nodes 4,5, and 6 are children of node 2.
- Sibling: Nodes 4,5, and 6 are siblings of each other.
- Leaf nodes: Nodes 9,10, and 11 are leaf nodes because they do not have any children.
Properties of a tree:
- The number of edges: A tree with ‘n’ nodes, will have (n-1) edges.
- Depth: The length of the path from the root node to the node ‘x’, is the depth of that particular node. Example: Node 2 has depth 1.
- Height: The longest path from node ‘x’ to the leaf node is the height of that particular node.
Commonly asked interview questions on the tree:
- What is a binary search tree?
- What is a self-balanced tree?
- How to find the distance between two nodes in a binary search tree?
Hash table
A Hash table is a data structure which is used to store key, value pairs after hashing. Since each value has its own unique key/index, the operations on the hash table are really fast.
Hashing is a process where we use a hash function to convert input values into hash values/hash keys as shown below:
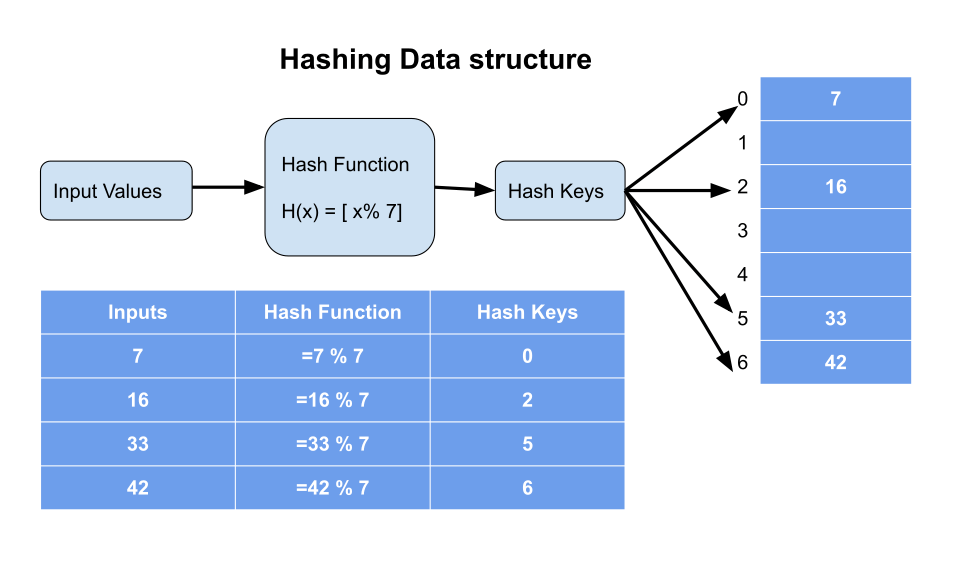
- Input values are fed into the hash function, which then provides hash keys after processing.
- These hash keys act as the index where input values are stored.
Operations on hash tables:
- Insert: It inserts an input value in the hash table.
- Delete: It deletes an input value from the hash table.
- Search: Searches data in the hash table using the hash key.
Common interview questions on the hash table:
- What are the advantages of Binary Search Tree(BST) over hash tables?
- What do you know about the space complexity of hash tables?
- Write an algorithm to find if an array is a subset of another array using hashing.
Infix, postfix, prefix notation
Notation defines the placement of operators and operands in an arithmetic/logical expression. They can be of three types:
- Infix: Where the operator is placed between the operands.
Example: A+B
We read and understand infix notation, but it is costly for a computer in terms of processing time. Hence, there are two other notations which the compiler/computer uses for processing.
- Postfix: Where the operator is placed after the operands.
Example: AB+
- Prefix: Where the operator is laced before the operands.
Example: +AB
Table below provides a few more examples of these notations.
| Infix | Prefix | Postfix |
| a + b | + a b | a b + |
| (a + b) ∗ c | ∗ + a b c | a b + c ∗ |
| a ∗ (b + c) | ∗ a + b c | a b c + ∗ |
| a / b + c / d | + / a b / c d | a b / c d / + |
The stack data structure in notations:
Usually, to convert an arithmetic expression into the other notations, the stack data structure is used. Example: To find out if the arithmetic expression has balanced parentheses, a stack will be used. For every open parenthesis, the operation push is performed and parentheses are pushed into the stack. For every close parenthesis in the arithmetic expression, operation pop is performed and parentheses are read from the stack.
At the end of the expression, if the stack is empty then the parentheses were balanced, if it is not empty then there was a mismatch in the parentheses.
Read in detail regarding expression parsing here.
Common interview questions on notations:
Mostly the questions will be based on conversions as:
Convert ((A + B) * C - (D - E) ^ (F + G)) into postfix and prefix notation.
Differences between linked list and array.
| Linked list | Array |
| New elements can be allocated with memory anywhere and a pointer to that location is stored. | The contiguous memory location is allocated for the whole array. |
| Memory allocation is dynamic, during run-time. | Memory allocation is static, during compile time. |
| Size is dynamic and can be changed during runtime. | The size of the array is fixed. |
| Elements are accessed in sequential order. | Elements can be accessed randomly through the indexes. |
| Insertion and deletion are easy and quick. | Insertion and deletion are time-consuming. |
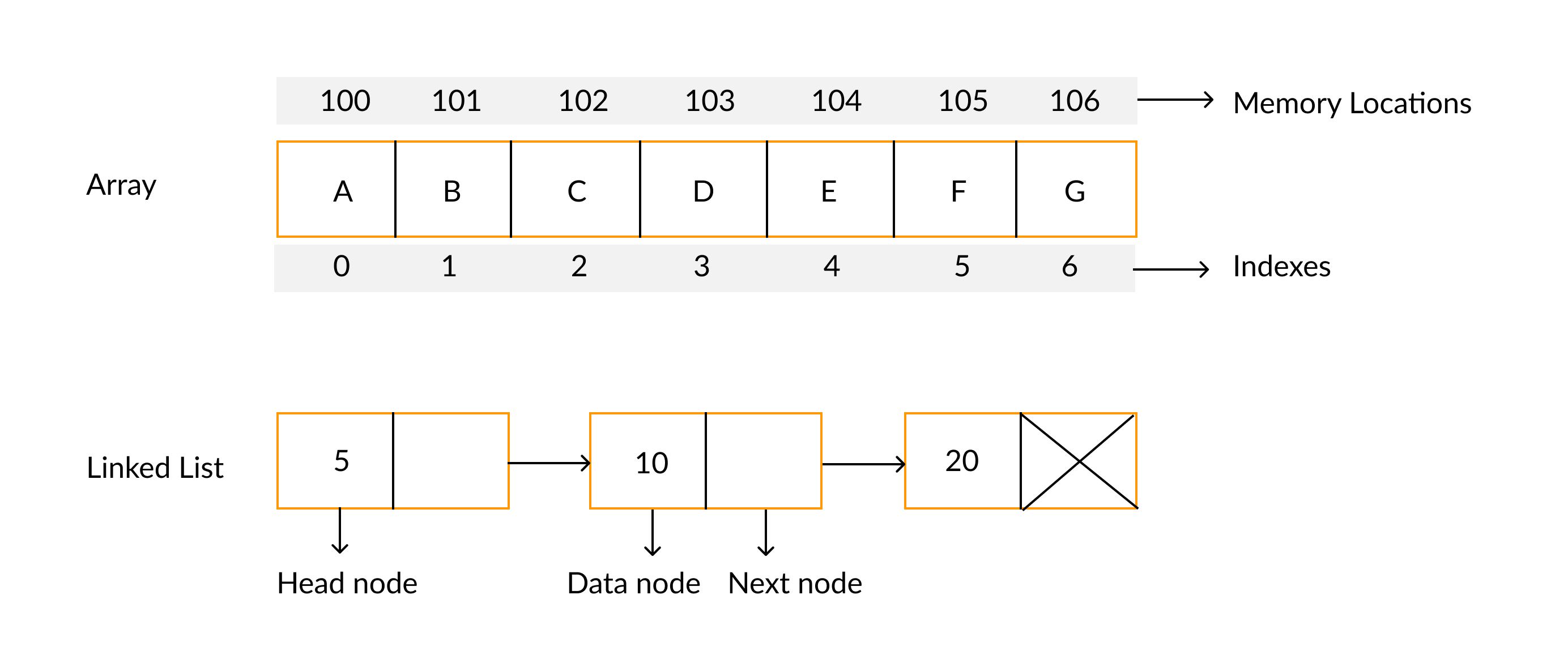
Image credit: faceprep.in
Popular interview topics on algorithms
Recursion
Recursion means repetition, the function repeats calling itself until the logical problem is solved. Therefore, we need to provide two conditions during recursion:
- Base condition: Which ensures that the problem is solved and the function can stop calling itself.
- Recursive condition: Which ensures that the problem is still not solved and the function needs to call itself again.
In the below example we want to print a countdown starting from a number(i) till we print number one(1).
- Base condition: We will continue printing the numbers till we reach number one(1) as mentioned in the base condition.
- Recursive condition: We will call the ‘countdown’ function recursively with value (i-1).
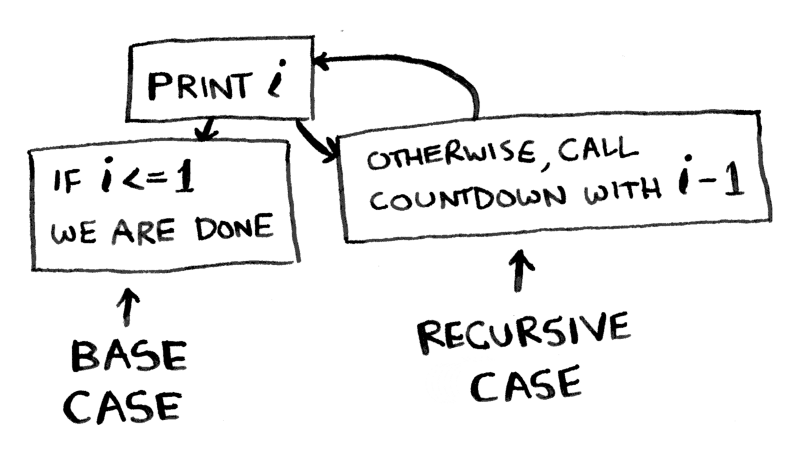
Recursion is a programming technique, where the function can call itself and solve a logical problem. Recursion helps solve problems such as the tower of Hanoi, Fibonacci series, the factorial of a number, graph DFS, etc. Here, the recursive function calls itself either directly or indirectly until it reaches the program’s exit criteria, i.e. the base condition. There are two base conditions in this algorithm:
- If Fibonacci(1) then return 1
- If Fibonacci(0) then return 0
Example:
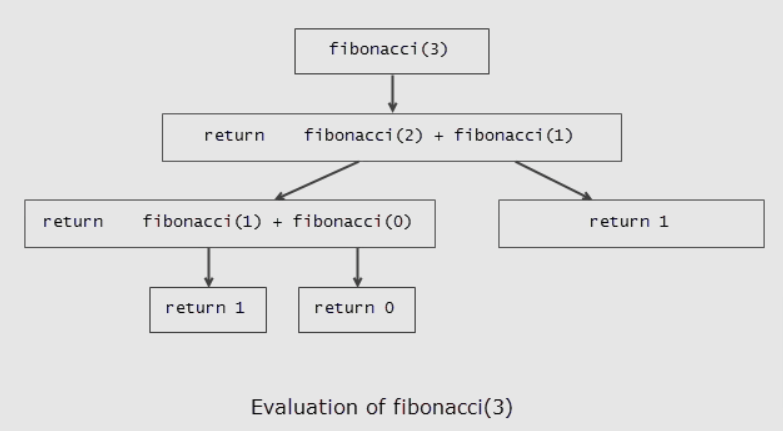
Let us calculate the Fibonacci(3) using recursion.
- Fibonacci(3) function calls Fibonnaci(1) + Fibonacci(2).
- Fibonacci(1) reaches the base condition (exit criteria) and returns 1.
- Fibonacci(2) further calls the function Fibonacci(1) + Fibonacci(0).
- Fibonacci(0) reaches base condition and returns 0.
- Now the Fibonnaci(1) reaches the base condition and returns 1.
- All the values are substituted for the functions and then the final result is calculated, as below.
Bubble sort
It is a sorting algorithm, which is used to sort data structures in ascending or descending order. In this algorithm, we will compare the adjacent data elements for order, if they are in order no action is needed. If they are not in order then we will swap them to bring them in order.
Let’s see an example, we have a list as (6 2 5 3 9)
- First Pass:
( 6 2 5 3 9 ) –> ( 2 6 5 3 9 ), Compare the first two elements, and swap as 6 > 2.
( 2 6 5 3 9 ) –> ( 2 5 6 3 9 ), Swap as 6 > 5
( 2 5 6 3 9 ) –> ( 2 5 3 6 9 ), Swap as 6 > 3
( 2 5 3 6 9 ) –> ( 2 5 3 6 9 ), Already in order (9 > 6), no need to swap.
- Second Pass:
( 2 5 3 6 9 ) –> ( 2 5 3 6 9 )
( 2 5 3 6 9 ) –> ( 2 3 5 6 9 ), Swap as 5 > 3
( 2 3 5 6 9 ) –> ( 2 3 5 6 9 )
( 2 3 5 6 9 ) –> ( 2 3 5 6 9)
When there is a complete pass without any swap then the list is sorted as below.
- Third Pass:
( 2 3 5 6 9 ) –> ( 2 3 5 6 9 )
( 2 3 5 6 9 ) –> ( 2 3 5 6 9 )
( 2 3 5 6 9 ) –> ( 2 3 5 6 9 )
( 2 3 5 6 9 ) –> ( 2 3 5 6 9 )
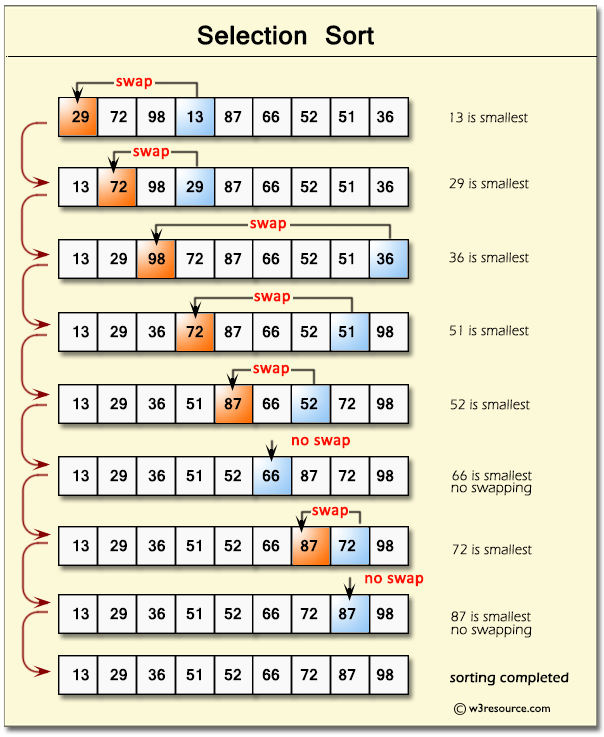
Selection sort
It is better than bubble sort since this will make only one exchange per pass.
- Select the first element in the list as smallest in a variable ‘minimum’.
- Compare it with the second element if the second is smaller, then assign second to ‘minimum’, else continue comparing with the third, fourth, and so on.
- Hence in every pass, we will get the minimum element in the list.
- After every pass, the minimum will be swapped at the appropriate position. E.g., at the first position in the first pass, the second position in the second pass, etc.
Insertion sort
It is more efficient than bubble and selection sort. In insertion sort, the correct order element is inserted at its appropriate position. An element is compared with all the elements on its left side and then inserted accordingly as shown below. The element marked as green in the image below is being compared to all the elements on its left. And when the smallest element is found it is inserted at its appropriate position in every pass.

Binary search
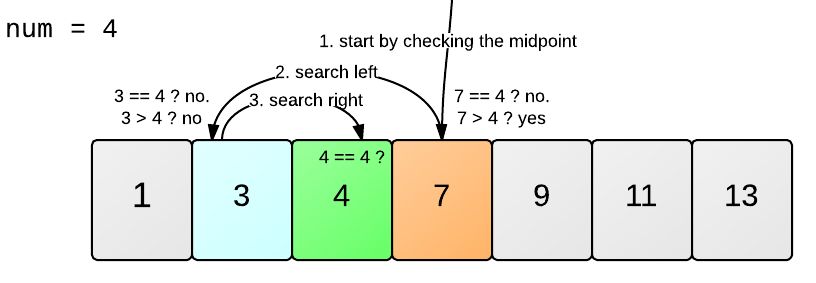
It is the most efficient searching algorithm since it searches half of the list according to the element to be searched. For this purpose, we require an already sorted list.
Start the search from the mid element.
If the number to be searched is greater than the middle element then it goes to the right side of the list else it will search on the left side as shown below:
- We want to search number 4 in the list, so we start from the mid element i.e. 7.
- If 7>4 then search in the left half, by comparing with the mid element.
- If 3>4 then search the left half, else go to the right.
- In the right half, we found the number 4.
Implementation of queue using stack and vice-versa
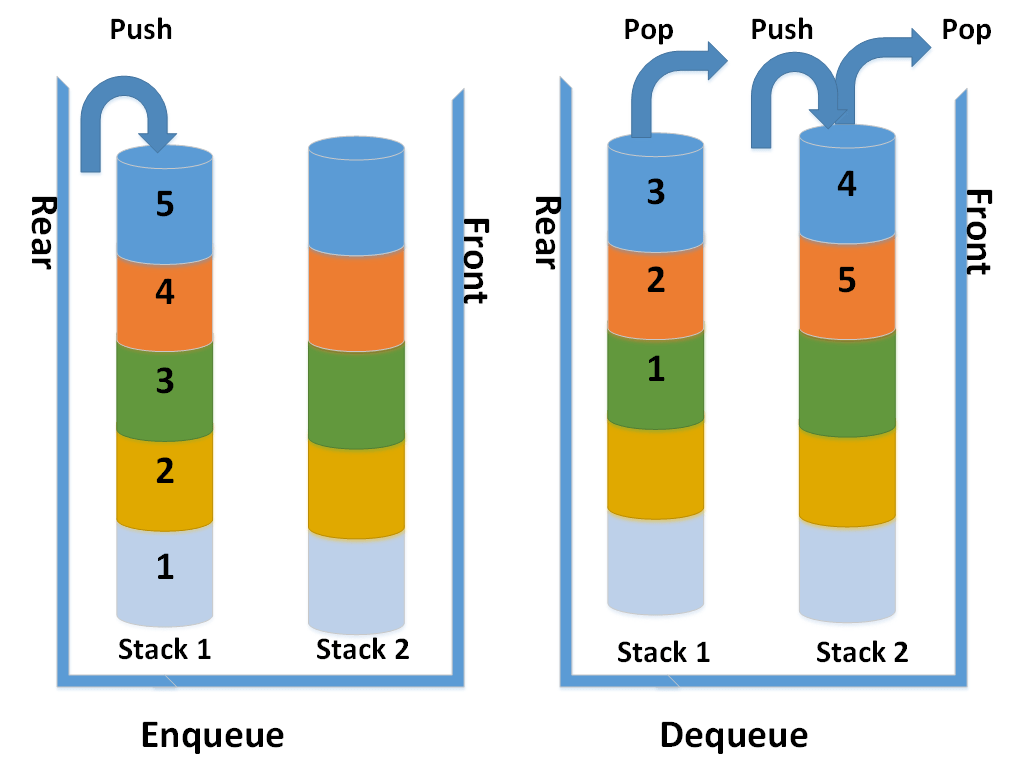
Implementation of queue using stack
Queue works on the First-in-first-out principle and stack works on First-in-last-out. A queue has one entry point and another exit point, while a stack has a single entry and exit point.
We can implement a queue using two stacks. When we need to push an element, we add the element in Stack 1. When we need to pop the element, we need to do it from Stack 2.
Enqueue operation:
It is the operation to add the element into the queue.
Algorithm for Insertion
- Take two stacks Stack 1 and Stack 2
- If Stack 1 is empty then insert directly into Stack 1.
- If Stack 1 is not empty then push all the elements from Stack 1 to Stack 2.
- Push element to be inserted into Stack 1.
- Push all elements from Stack 2 into Stack 1.
Dequeue:
It is the operation to remove the element from the queue.
Algorithm for Deletion
- Pop out the element from Stack 1, if Stack 1 is not empty.
- If Stack 1 is not empty then return -1.
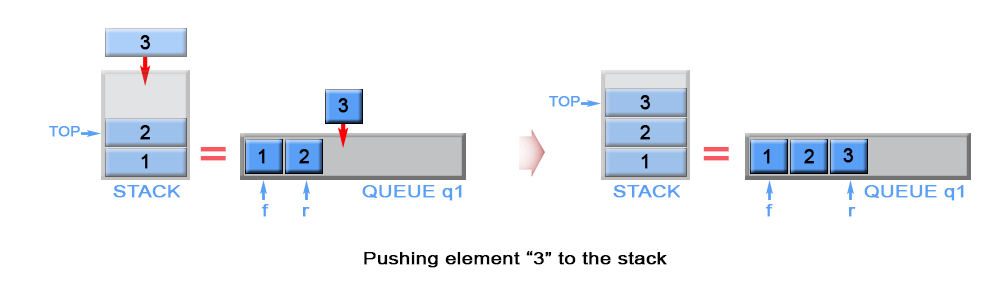
Implementation of stack using queue
We will use two queues for the implementation of the stack.
- Push operation:
When we want to push a new element e.g. number 3 in an existing stack, we can place the element at the end of the rear of the queue.
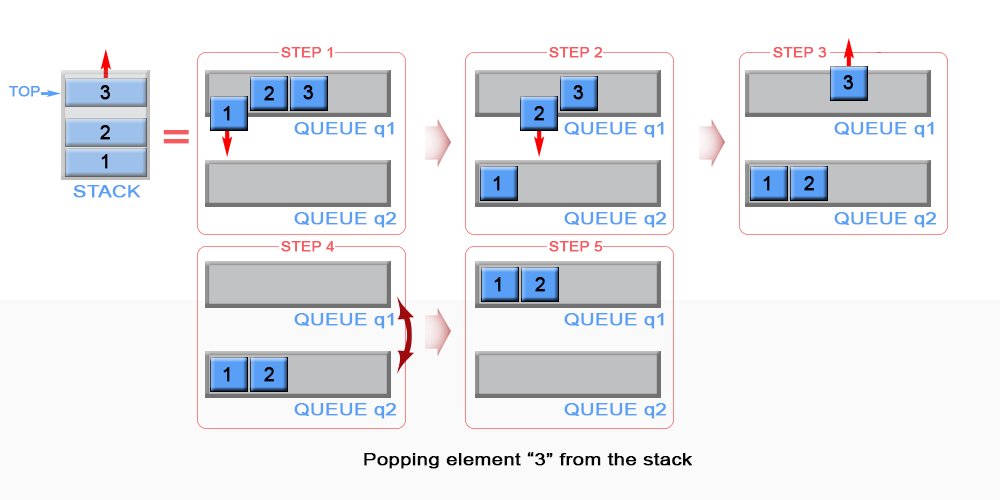
2. Pop operation:
For implementing pop operation, we will use two queues q1 and q2.
- Move elements from q1 to q2 one by one, except the last element.
- Now remove the element from q1 i.e. pop the element.
- Move elements back to q1 from q2.
Other Backend Technology Interview Questions and Answers
C Programming Language Interview Questions | PHP Interview Questions | .NET Core Interview Questions | NumPy Interview Questions | API Interview Questions | FastAPI Python Web Framework | Java Exception Handling Interview Questions | OOPs Interview Questions and Answers | Java Collections Interview Questions | System Design Interview Questions | Node.js Interview Questions | Django Interview Questions | React Interview Questions | Microservices Interview Questions | Key Backend Development Skills | Data Science Interview Questions | Python Interview Questions | Java Spring Framework Interview Questions | Spring Boot Interview Questions.


