

DBMS Interview Questions and Answers 2023

DBMS, or Database Management System, is the key to working with databases. It is a software application that lets you create, manipulate, and manage databases in a fast and organised way. DBMS is vital for many software applications and is used in various industries. Hacker Trail's guide will help you to get ready for your DBMS interview.
This special guide will include the most frequent questions and answers for different skill levels, such as:
- Basic DBMS Interview Questions
- Intermediate DBMS Interview Questions
- Advanced DBMS Interview Questions
- Quick Review
DBMS Basic Interview Questions
1. What is DBMS and its Advantages?
DBMS stands for Database Management System. DBMS provides a structured and systematic approach to manage large volumes of data, ensuring data integrity, security, and efficient data access.
Key advantages of DBMS are:
- It provides data abstraction, which means users can access data without knowing the details of how it is stored and organised.
- It supports data integrity, which means it ensures that the data is accurate and consistent.
- It supports data security, which means it protects the data from unauthorised access and modification.
- It supports data independence, which means it allows changes in the data structure or storage without affecting the application programmes.
- It supports data sharing, which means it allows multiple users to access and manipulate the same data concurrently.
2. What is a Database?
Database is a collection of data that is organised and structured in a way that makes it easy to modify, access, and manage. It consists of tables or objects (any database object is created using the create command) that have records and fields. A record, or a row, is an entry in a table that represents an item or an entity. A field or a column is a unit of data storage that contains information about a specific aspect of the table. The user can retrieve data from a database using queries that are processed by the Database Management System (DBMS).
3. What is a Database System?
A database system consists of both database and DBMS software. It allows us to do various tasks, such as storing data in the database easily and avoiding problems of data duplication and inconsistency. We can use DBMS software to retrieve data from the database whenever we need it. Therefore, a database system helps us manage data with high accuracy and security.
4. What is DBMS and its Utility?
Database Management System (DBMS) is a software that helps users create and maintain databases. It offers tools and interfaces for performing operations like adding, deleting, and updating data in a database. DBMS software has advantages over file-based systems, such as more compact and secure data storage.
DBMS systems also solve problems such as data inconsistency and redundancy, making the databases more organised and convenient. You can learn more about DBMS from the DBMS Tutorial by Scaler Topics. Some examples of DBMS systems are file systems, XML, and the Windows Registry.
5. What is RDBMS?
RDBMS is a type of DBMS that stores and accesses data in tables using relations. It lets you perform various operations on a relational database, such as update, insert, delete, manipulate, and administer. RDBMS often uses SQL language because it is easy and common.

6. How Many Types of Database Languages Exist?
Database languages are the queries that are used to change, modify, and handle the data. There are four types of database languages:
- Data Definition Language (DDL) e.g., CREATE, ALTER, DROP, TRUNCATE, RENAME, etc. These commands are used to update the data structure and schema.
- Data Manipulation Language (DML) e.g., SELECT, UPDATE, INSERT, DELETE, etc. These commands are used to manipulate the data values and records.
- DATA Control Language (DCL) e.g., GRANT and REVOKE. These commands are used to give and remove user access rights on the database.
- Transaction Control Language (TCL) e.g., COMMIT, ROLLBACK, and SAVEPOINT. These commands are used to manage transactions in the database and undo or save the changes made by DML.
7. What is SQL and What are its Features?
SQL stands for Structured Query Language. It is a programming language for storing and processing information in a relational database. Some of its features are:
- It is declarative which means it specifies what to do not how to do it.
- It is high-level which means it abstracts from low-level details of data storage and manipulation.
- It is versatile which means it can perform various tasks such as data definition, data manipulation, data query, data control, etc.
- It is portable which means it can run on different platforms and databases with minimal changes.
- It is interactive which means it can be used by humans to communicate with databases.
- It is modular which means it can be embedded in other programming languages or applications.
8. What are the Types of SQL Statements?
SQL statements can be classified into five types based on the functionalities performed by them:
- Data definition language (DDL)
- Data manipulation language (DML)
- Data query language (DQL)
- Data control language (DCL)
- Transaction Control Language (TCL).
9. What are the Differences between DDL and DML?
Few differences between DDL and DML are:
- DDL is used to define the structure and constraints of the data in the database, while DML is used to manipulate the data in the database.
- DDL statements are executed once when the database is created or modified, while DML statements are executed repeatedly whenever the data is inserted, updated, or deleted.
- DDL statements affect the metadata of the database, while DML statements affect the actual data of the database.
- DDL statements cannot be rolled back or undone, while DML statements can be rolled back or undone using transactions.
10. What are the differences between DQL and DCL?
Some of the differences between DQL and DCL are:
- DQL is used to query or retrieve the data from the database, while DCL is used to control the access and security of the data in the database.
- DQL statements are executed by users or applications to get information from the database, while DCL statements are executed by administrators or owners to grant or revoke privileges to users or roles.
- DQL statements return a result set of data, while DCL statements do not return any result set.
- DQL statements do not change the state of the database, while DCL statements may change the state of the database.
11. What are Some of the Basic SQL Commands?
Some of the basic SQL commands are:
- CREATE: It is used to create a new table, view, index, or other database object.
- ALTER: It is used to modify an existing table, view, index, or other database object.
- DROP: It is used to delete an existing table, view, index, or other database object.
- INSERT: It is used to insert one or more rows of data into a table.
- UPDATE: It is used to update one or more rows of data in a table.
- DELETE: It is used to delete one or more rows of data from a table.
- SELECT: It is used to query or retrieve data from one or more tables or views.
- JOIN: It is used to combine data from two or more tables or views based on a common condition.
- GROUP BY: It is used to group rows of data based on one or more columns and apply aggregate functions on them.
- ORDER BY: It is used to sort rows of data based on one or more columns in ascending or descending order.
12. What are Some Examples of SQL Functions?
SQL functions are database objects that perform calculations or manipulations on data and return a result. SQL functions are divided into two types:
- Aggregate functions: These functions operate on a set of values and return a single value that summaries them. For example, SUM returns the sum of values, AVG returns the average of values, MIN returns the minimum value, MAX returns the maximum value, and COUNT returns the number of values.
- Scalar functions: These functions operate on a single value and return a single value that modifies it. For example, ABS returns the absolute value, ROUND returns the rounded value, SQRT returns the square root value, LEN returns the length of the value, UPPER converts the value to uppercase, and LOWER converts the value to lowercase.
13. Are NULL Values in a Database the Same as Blank Space or Zero?
A NULL value means that the value is either missing, unknown, or not applicable. It is different from zero or blank space, which are actual values.
For example: If a student has NULL in the “number_of_courses” column, it means we do not know how many courses they have taken. If they have zero, it means they have taken no courses.
14. What is Data Warehousing?
Data warehousing is the process of storing data from multiple sources in one database for data analytics. It is a central repository of an organisation’s historical data that helps in decision-making. A data warehouse collects, extracts, transforms, and loads data from transactional systems and other databases.
15. Explain Different Levels of Data Abstraction in a DBMS.
Data abstraction is the technique of concealing irrelevant details from users. There are 3 levels of data abstraction:
- Physical Level: This is the lowest level, and it describes how data is stored by DBMS. This level is usually hidden from everyone.
- Conceptual or Logical level: This is the level where developers and system admins work and it defines what data and relationships are in the database.
- External or View level: This is the level that shows only part of database, and it hides the table schema and physical storage from users. A query result or a view is an example of this level. A view is a virtual table made from one or more tables in the database.

Intermediate DBMS Interview Questions
16. Explain the Different Languages in DBMS.
DBMS uses various languages to perform different tasks on the database. Some of these languages are:
- DDL (Data Definition Language): This language defines the structure and schema of the database. It includes commands such as CREATE, ALTER, DROP, TRUNCATE, and RENAME.
- DML (Data Manipulation Language): This language manipulates the data stored in the database. It includes commands such as SELECT, UPDATE, INSERT, and DELETE.
- DCL (Data Control Language): This language controls the access and permissions of database users. It includes commands such as GRANT and REVOKE.
- TCL (Transaction Control Language): This language manages the transactions that occur on the database. It includes commands such as COMMIT, ROLLBACK, and SAVEPOINT.
17. What are the Drawbacks of Traditional File-Based Systems That Make DBMS a Better Choice?
Traditional file-based systems have many drawbacks that make data access difficult and inefficient. Some of these drawbacks are:
- Lack of indexing: The only way to find data in a file is to scan the entire file, which is slow and tedious.
- Redundancy and inconsistency: Files may contain duplicate and unnecessary data, which wastes space and causes inconsistency when one copy of the data is changed but not the others.
- Lack of concurrency control: Files may be locked by one operation, preventing other operations from accessing them at the same time, as opposed to DBMSs where multiple operations can work on the same file concurrently.
- Other issues: Files may not have mechanisms to ensure integrity, isolation, atomicity, security, and other desirable properties of data management, which are provided by DBMSs.
18. What is Meant by ACID Properties in DBMS?
DBMS uses the ACID properties to ensure reliable and secure data sharing among multiple users. The ACID properties are:
- Atomicity: A transaction must either succeed completely or fail. Atomicity ensures that the database does not have any incomplete updates.
- Consistency: This property means that a transaction preserves the integrity and validity of the data. It ensures that the database follows the defined rules and constraints before and after a transaction.
- Isolation: This property means that a transaction is isolated from other concurrent transactions. It prevents interference or conflicts that could compromise the accuracy of the data.
- Durability: This property means that a transaction is permanent and persistent. It guarantees that the data is not lost or corrupted in case of a system failure or restart.
19. What are Some of the SQL Operators?
Some of the SQL operators are:
- Arithmetic operators: They are used to perform mathematical calculations on numeric values, such as + (addition), - (subtraction), * (multiplication), / (division), % (modulo), etc.
- Comparison operators: They are used to compare two values and return a Boolean result, such as = (equal), <> (not equal), > (greater than), < (less than), >= (greater than or equal), <= (less than or equal), etc.
- Logical operators: They are used to combine two or more Boolean expressions and return a Boolean result, such as AND (logical and), OR (logical or), NOT (logical not), etc.
- Set operators: They are used to perform set operations on two result sets and return a new result set, such as UNION (set union), INTERSECT (set intersection), EXCEPT (set difference), etc.
20. Define a Relation Schema and a Relation
Relation Schema is a set of attributes that defines the name and structure of a table. It is like a blueprint that shows how data is organised into tables. It does not contain any data. A relation is a set of tuples that represents the data in a table. A tuple is an ordered list of values that are related by key attributes. For example, if r is a relation with tuples (t1, t2, t3, …, tn), then each tuple has n values: t= (v1, v2, …, vn).
21. What is a Degree of Relation?
The degree of relation is an attribute of the relation schema that indicates how many instances of one entity are associated with how many instances of another entity. The degree of relation is also called cardinality. There are three types of degree of relation: one-to-one (1:1), one-to-many (1:M), and many-to-many (M:M).
22. What are the Integrity Rules in DBMS?
Data integrity is a key aspect of database maintenance, which involves applying a set of rules to ensure the data is reliable and accurate. These rules are known as integrity rules in DBMS, and they consist of two types: Entity Integrity: This rule requires that “The primary key cannot have a NULL value.” Referential Integrity: This rule allows that “The foreign key can be either a NULL value or the same as the primary key value of another relation.”
23. What is the E-R Model?
E-R model stands for Entity-Relationship model, which is a model based on the real world. It includes relevant objects (called entities) and the relationship between them. The main components of the E-R model are the entity, the attribute of the entity, the relationship set, and the attribute of the relationship set. These components can be shown in an E-R diagram, where entities are rectangles, relationships are diamonds, attributes are ellipses, and data flow is a straight line.
24. What is Data Abstraction in DBMS?
Data abstraction in DBMS is a way of hiding unnecessary details from users. Database systems have complex data structures, so data abstraction makes it easier for users to interact with the database. For example, most users prefer simple GUIs that do not show complex processing. Data abstraction helps to keep the users engaged and simplify the data access. It also separates the system into different layers to make the tasks specific and clear.
25. What are the 3 levels of Data Abstraction?
There are three levels of data abstraction in DBMS:
- Physical level: This is the lowest level of abstraction. It shows how data are stored physically.
- Logical level: This is the next higher level of abstraction. It shows what data are stored in the database and how they are related.
- View level: This is the highest level of abstraction. It shows only a part of the whole database.
26. What is a Primary Key and a Foreign Key? How are They Different?
A primary key is a column or a set of columns that uniquely identifies each row in a table. A foreign key is a column or a set of columns that references the primary key of another table. The difference between them is that a primary key ensures uniqueness within a table, while a foreign key ensures consistency across tables.
27. What is Normalisation and Denormalisation? What are Their Benefits and Drawbacks?
Normalisation is the process of organising the data in a database into smaller and less redundant tables. Denormalisation is the process of combining the data from multiple tables into larger and more redundant tables.
The benefits of normalisation are that it reduces data anomalies, improves data integrity, and simplifies query writing. The drawbacks of normalisation are that it increases the number of tables and joins, which may affect performance and complexity.
The benefits of denormalisation are that it improves query performance and reduces the number of joins. The drawbacks of denormalisation are that it increases data redundancy, storage space, and updates anomalies.
28. What is an Index and How Does It Improve Query Performance?
An index is a data structure that stores a subset of the data in a table based on one or more columns. It allows faster retrieval of data by providing a direct pointer to the location of the data in the table. It improves query performance by reducing the number of disk accesses and comparisons needed to find the data.
29. What is a Transaction and What are Its Properties?
A transaction is a logical unit of work that consists of one or more operations on the database. A transaction has four properties: Atomicity, Consistency, Isolation, and Durability (ACID). Atomicity means that either all or none of the operations in a transaction are executed. Consistency means that the database state remains valid before and after a transaction. Isolation means that each transaction is executed as if it were the only one in the system. Durability means that the effects of a transaction are permanent even in case of failures.
30. What is Concurrency Control and What are Some Common Techniques for Implementing it?
Concurrency control is the process of managing simultaneous access to the database by multiple transactions. Some common techniques for implementing concurrency control are locking, timestamping, and optimistic validation.
Locking is the technique of granting exclusive or shared access to a resource to prevent conflicts.
Timestamping is the technique of assigning a unique identifier to each transaction based on its start time or commit time to determine its precedence.
Optimistic validation is the technique of allowing transactions to execute without interference and validating their results at commit time.

Advanced DBMS Interview Questions
31. Explain the Difference Between Intension and Extension in a Database.
Following is the major difference between intension and extension in a database:
- Intension: Intension or popularly known as database schema is used to define the description of the database and is specified during the design of the database and mostly remains unchanged.
- Extension: Extension on the other hand is the measure of the number of tuples present in the database at any given point in time. The extension of a database is also referred to as the snapshot of the database and its value keeps changing as and when the tuples are created, updated, or destroyed in a database.
32. Explain the Difference Between DELETE and TRUNCATE Command in a DBMS.
DELETE command: this command is needed to delete rows from a table based on the condition provided by the WHERE clause.
- It deletes only the rows which are specified by the WHERE clause.
- It can be rolled back if required.
- It maintains a log to lock the row of the table before deleting it and hence it is slow.
TRUNCATE command: this command is needed to remove complete data from a table in a database. It is like a DELETE command which has no WHERE clause.
- It removes complete data from a table in a database.
- It cannot be rolled back even if required. (Truncate can be rolled back in some databases depending on their version but it can be tricky and can lead to data loss). Check this link for more details.
- It does not maintain a log and deletes the whole table at once and hence it is fast.
33. What is a Lock? Explain the Major Difference Between a Shared Lock and an Exclusive Lock during a Transaction in a Database.
A database lock is a mechanism to protect a shared piece of data from getting updated by two or more database users at the same time. When a single database user or session has acquired a lock then no other database user or session can modify that data until the lock is released.
- Shared Lock: A shared lock is required for reading a data item and many transactions may hold a lock on the same data item in a shared lock. Multiple transactions are allowed to read the data items in a shared lock.
- Exclusive Lock: An exclusive lock is a lock on any transaction that is about to perform a write operation. This type of lock does not allow more than one transaction and hence prevents any inconsistency in the database.
34. Explain different types of Normalisation forms in a DBMS
Normalisation in DBMS is a technique that helps to design the schema of a database optimally. It reduces data redundancy and prevents data anomalies. Normalisation works through a series of stages called normal forms, which apply certain constraints to the relations. The most used normal forms are:
- First Normal Form (1NF): This normal form requires that every attribute of a relation must have an atomic value, i.e., it cannot be divided into smaller parts. It also requires that every relation must have a primary key, which is a unique identifier for each tuple.
- Second Normal Form (2NF): This normal form requires that a relation must be in 1NF, and every non-key attribute must be fully functionally dependant on the primary key, i.e., it cannot depend on a part of the primary key or another non-key attribute. This eliminates partial dependencies.
- Third Normal Form (3NF): This normal form requires that a relation must be in 2NF, and every non-key attribute must be non-transitively dependant on the primary key, i.e., it cannot depend on another non-key attribute that depends on the primary key. This eliminates transitive dependencies.
- Boyce-Codd Normal Form (BCNF): This normal form is a stronger version of 3NF that requires that every determinant of a relation must be a candidate key, i.e., it can uniquely identify each tuple. This eliminates any functional dependencies that are not implied by the candidate keys.
There are other higher normal forms, such as 4NF and 5NF, but they are less commonly used and more complex to understand. They deal with issues such as multi-valued dependencies and join dependencies.
35. Explain Different Types of Keys in a Database.
A database has 7 types of keys that are used to identify and relate tuples in a table. They are:
- Candidate Key: A set of attributes that can uniquely identify a tuple in a table. A table can have more than one candidate key. One of the candidate keys can be selected as the primary key. For example, studentId and firstName are candidate keys for the student table, as they can distinguish each tuple.
- Super Key: A set of attributes that can also uniquely identify a tuple in a table. The super key is a superset of the candidate key and the primary key. For example, studentId, firstName, and lastName are a super key for the student table, as they can also identify each tuple.
- Primary Key: A set of attributes that are chosen to be the main identifier for a tuple in a table. The primary key does not allow NULL values in the column. For example, studentId is the primary key for the student table, as it is used to identify each tuple.
- Unique Key: A set of attributes that are like the primary key, except that they allow NULL values in the column. The unique key can also uniquely identify a tuple in a table. For example, firstName is a unique key for the student table, as it can also identify each tuple, but it can have NULL values.
- Alternate Key: All the candidate keys that are not selected as the primary key are called alternate keys. They can also uniquely identify a tuple in a table. For example, firstName and lastName are alternate keys for the student table, as they are not chosen as the primary key.
- Foreign Key: A set of attributes that refer to another table’s primary key or unique key. The foreign key can only take values that exist in the other table’s column. For example, courseId is a foreign key for the student table, as it refers to the course table’s primary key or unique key.
- Composite Key: A combination of two or more attributes that can uniquely identify a tuple in a table. For example, studentId and firstName are a composite key for the student table, as they can together identify each tuple.
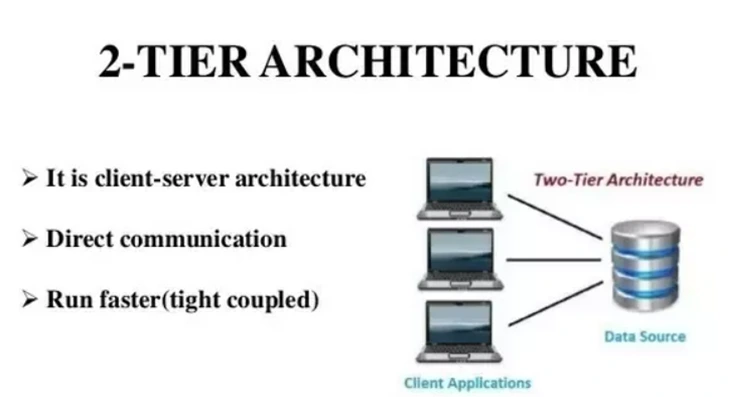
36. Explain the Difference Between a 2-Tier and 3-Tier Architecture in a DBMS.
A 2-tier architecture is a type of client-server architecture where the client application directly communicates with the database server without any intermediate layer. For example, a contact management system using MS-Access or a railway reservation system.
The diagram below shows a 2-tier architecture in a DBMS.
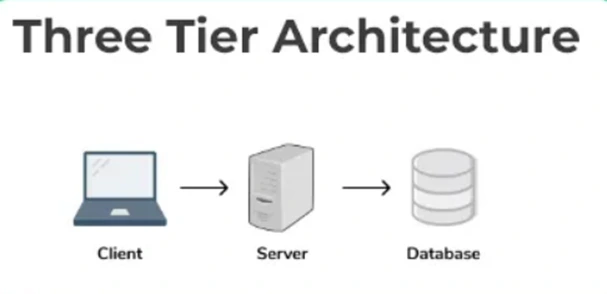
A 3-tier architecture is another type of client-server architecture where there is an additional layer between the client and the server to provide a graphical user interface (GUI) to the users and to enhance the security and accessibility of the system. In this type of architecture, the client application interacts with a server application that further communicates with the database system. For example, a registration form with text boxes, labels and buttons or a large website on the internet.
The diagram below shows a 3-tier architecture in a DBMS
37. What are Materialised Views in DBMS? How do They Differ from Regular Views, and What Advantages do They Offer?
Materialised views are a type of database object that store the results of a query as a physical table. They are different from regular views, which are virtual tables that do not store any data but only show the results of a query on demand.
Materialised views offer several advantages over regular views, such as:
- Improved Query Performance: Materialised views can improve the performance of queries by precomputing and caching the results. This reduces the need to access the underlying tables or remote databases, resulting in faster query execution times.
- Query Optimisation Through Query Rewrite: Materialised views enable query rewrite, an optimisation technique that replaces a query on the base tables with a semantically equivalent query on the materialised view, if it is more efficient. This allows the database to automatically use the materialised view for query processing, leading to improved performance.
- Support for Data Replication and Data Warehousing: Materialised views can be used to maintain copies or summaries of remote or local data. This is particularly useful in scenarios where data needs to be replicated or aggregated for reporting, data analysis, or data integration purposes.
However, materialised views also have some drawbacks:
- Increased Storage Requirements: Materialised views consume more storage space than regular views since they store the query results as a table. This is because the data is physically stored rather than being derived on-the-fly like in regular views.
- Need for Periodic Refreshment: Materialised views require periodic refreshment to keep the data consistent with the base tables or remote databases. This refreshment process can add overhead and may impact the overall system performance.
- Restrictions on query types and refresh methods: Depending on the database system and the specific features of the materialised view, there may be restrictions on the types of queries that can be executed against the view and the methods available for refreshing the data. These restrictions can limit the flexibility and applicability of materialised views in certain scenarios.
Overall, materialised views provide a trade-off between improved query performance and increased storage and maintenance requirements. They are particularly beneficial in situations where query performance is critical, and the data can tolerate periodic refreshes to ensure consistency.
38. What is the difference between a clustered index and a non-clustered index? Discuss the scenarios in which each type of index is more appropriate.
A clustered index and a non-clustered index are two types of indexes used in a database management system. Here is the difference between them and the scenarios in which each type of index is more appropriate:
1. Clustered Index:
- A clustered index determines the physical order of data rows in a table.
- A table can have only one clustered index.
- The order of the clustered index determines the order of the data on disk.
- In a clustered index, the data rows are physically organised based on the indexed column(s).
- Clustered indexes are particularly useful for improving the performance of queries that involve range-based searches or when there is a need for sorting and accessing data based on a specific column.
- Clustered indexes are ideal for tables that are frequently accessed and require efficient retrieval of data.
Scenarios where a clustered index is more appropriate:
- Large tables where range-based queries (e.g., retrieving all records between a certain date range) are common.
- Tables that require frequent sorting or grouping operations based on a specific column.
- Tables with columns that have unique or sequential values (e.g., an ID column).
2. Non-Clustered Index:
- A non-clustered index is a separate structure that contains a copy of the indexed column(s) along with a pointer to the actual data rows.
- A table can have multiple non-clustered indexes.
- Non-clustered indexes do not dictate the physical order of data rows in a table.
- Non-clustered indexes are useful for improving the performance of queries that involve searching, filtering, and joining operations.
- They provide efficient access to specific data rows based on the indexed column(s).
Scenarios where a non-clustered index is more appropriate:
- Tables with columns are frequently used in search predicates (WHERE clauses).
- Tables involved in join operations, as non-clustered indexes, can improve the efficiency of join queries by providing quick access to the required data.
- Tables where data modification operations (INSERT, UPDATE, DELETE) are more frequent, as non-clustered indexes have less impact on these operations compared to clustered indexes.
39. What are the Various Backup and Recovery Techniques in DBMS? What Factors Should be Considered When Designing a backup and recovery strategy?
Backup and recovery techniques in DBMS help prevent data loss and restore data after failures or disasters. Some common techniques are:
- Full backups: copy the entire database
- Incremental backups: copy the changes since the last backup
- Differential backups: copy the changes since the last full backup
- Transaction log backups: copy the transactions
- Point-in-time recovery: restore the database to a specific moment
Some factors to consider when designing a backup and recovery strategy are:
- Recovery Point Objective: how much data loss is acceptable
- Recovery Time Objective: how fast the recovery should be
- Storage and Bandwidth: how much space and network resources are needed
- Testing and Validation: how to ensure the backups are valid and recoverable
- Security: how to protect the backups from unauthorised access
- Automation and Monitoring: how to automate and track the backup processes
40. What is a deadlock in the context of database systems? How can deadlocks be detected and resolved?
A deadlock occurs when two or more transactions are waiting indefinitely for each other to release resources, resulting in a state of deadlock where no progress can be made. Deadlocks can lead to system performance degradation and even system failure if not resolved.
Deadlocks can be detected through various methods such as resource allocation graphs, wait-for graphs, and timeout-based approaches. Once detected, deadlocks can be resolved through techniques like deadlock detection and termination, deadlock prevention, and deadlock avoidance.
41. What is query optimisation in DBMS? Explain the Steps Involved in Query Optimisation
Query optimisation is the process of selecting the most efficient execution plan for a given query in a database system. It aims to minimise the response time and resource utilisation of queries by choosing the optimal access methods, join algorithms, and query execution plans.
The steps involved in query optimisation typically include query parsing and analysis, query transformation and rewriting, selection of appropriate indexes, join ordering, cost estimation, and plan generation. The optimiser evaluates different plan alternatives and selects the one with the lowest cost based on estimated execution time and resource usage.
42. What is the Difference Between a Join and a Subquery in DBMS? When Would You Choose One Over the Other?
A join combines rows from two or more tables based on a related column between them, while a subquery is a query embedded within another query.
A join is used to retrieve data from multiple tables simultaneously by matching common columns. It is suitable when data from multiple tables need to be merged into a single result set.
A subquery is used to retrieve data from one table based on the result of another query. It is useful when you need to perform operations like filtering, sorting, or aggregation on a subset of data before incorporating it into the main query.
43. Explain the Concept of Database Normalisation Forms Beyond Third Normal Form (3NF). What are the Benefits of Higher Normal Forms?
Beyond 3NF, higher normal forms like Boyce-Codd Normal Form (BCNF) and Fourth Normal Form (4NF) aim to eliminate additional types of data redundancies and dependencies.
BCNF eliminates all non-trivial dependencies on candidate keys, ensuring that each non-key attribute is functionally dependant on the entire candidate key. 4NF focuses on eliminating multi-valued dependencies, ensuring that each non-key attribute is depenant only on the key.
Benefits of higher normal forms include reduced data redundancy, improved data integrity, and simplified data maintenance. However, achieving higher normal forms may require additional data transformations and joins, which can impact query performance and complexity.
44. What is a Database Trigger? How can Triggers be used to Enforce Business Rules and Maintain Data Integrity?
A database trigger is a stored programme that is automatically executed in response to specific data manipulation events, such as insertions, updates, or deletions, occurring on a table.
Triggers can be used to enforce business rules and maintain data integrity by performing actions like validating data, implementing referential integrity, auditing changes, or updating related data.
For example, a trigger can be created to ensure that no sales orders with a total amount exceeding a certain limit are inserted into the database, thus enforcing a business rule.
45. Discuss the Advantages and Disadvantages of using NoSQL Databases Compared to Traditional Relational Databases.
Advantages of NoSQL databases include flexible data models, horizontal scalability, and high performance for certain use cases like handling big data, real-time data, or unstructured data. NoSQL databases can handle large amounts of data with high throughput and can easily scale horizontally by adding more servers.
However, NoSQL databases may have limitations in complex querying, lack of ACID transaction support, and reduced data consistency guarantees compared to traditional relational databases. NoSQL databases require careful consideration of data modelling and may not be suitable for applications that heavily rely on complex joins and transactions.
46. Explain the Concept of Database Replication. What are the Different Types of Database Replication and their Use Cases?
Database replication is the process of creating and maintaining multiple copies of a database to ensure data availability, fault tolerance, and scalability.
Different types of database replication include:
- Master-Slave Replication: In this type, one database server acts as the master, handling all write operations, while multiple slave servers replicate the changes from the master. It is useful for read-heavy workloads and provides high availability.
- Multi-Master Replication: In this type, multiple database servers can accept both read and write operations independently, and changes are propagated to all other servers. It is suitable for environments with high write concurrency and distributed application architectures.
- Snapshot Replication: It involves creating periodic snapshots of the entire database or specific tables and replicating them to other servers.


