

SQL Interview Questions and Answers 2023

Structured Query Language (SQL) is a programming language used to manage and manipulate relational databases. It provides an easy and efficient way to store, modify, and retrieve data from databases. SQL is a crucial tool for IT professionals, as it enables them to manage and work with data in a variety of contexts.
Techies with SQL knowledge can write complex queries, design and build efficient databases, and retrieve information in a structured and organised way. SQL is also an essential skill for Data Analysts, as it enables them to retrieve and analyse data from large databases and to generate reports.
Interviews for SQL roles are typically designed to test candidates' knowledge and experience with SQL. Candidates may be asked to write SQL queries, design and optimise databases, or analyse data using SQL. The interviewer may also ask questions about the candidate's experience with different database management systems and their ability to work with large datasets.
Our comprehensive interview Questions and Answers guide can help interviewees prepare for SQL-related questions. The guide covers topics such as SQL syntax, database design, and data analysis. Test yourself and see how much you know.
Table of Contents
Basic SQL Interview Questions and Answers
1. What is SQL?
SQL stands for Structured Query Language. It is a standard language to create, manipulate, store, and retrieve data from RDBMS. Through SQL we can perform the below actions on relational databases.
- Create - database, tables, views, stored procedures
- Update - records
- Insert - records
- Select - data from tables
- Set - permissions on tables, procedures, views
2. Explain briefly about DBMS.
DBMS stands for Database Management System. It is a software that works on databases, structured forms of storing data, from which data can be retrieved based on requests. It allows the user to store, modify, update, manage, retrieve data from the database.
DBMS acts as an interface between a user or an application and the database. DBMS receives queries, which are requests for data from the database, from the user and retrieves data from the database based on the queries.

3. What is RDBMS?
RDBMS stands for Relational Database Management System. RDBMS, like DBMS, supports access and management of data in a database. It helps the user to store, modify and retrieve from a relational database. In a relational database, there is a relationship between the data in the tables.
4. What is Dynamic SQL?
Unlike static SQL in which the SQL statements are pre-determined and coded in the application, ynamic SQL allows constructing SQL statements during runtime. Dynamic SQL executes statements that are not supported by static SQL programmes. When the full text of the SQL statements is not known until the runtime, the dynamic SQL is used like the application that may allow users to enter their own queries.
5. What are Tables in SQL?
A Table is a database object in which a set of data is stored logically in the form of columns and rows. The table has a specified number of columns, which represent the different fields, and has any number of rows that represents a record. Fields have data types such as text, dates, numbers.
In the table ‘Employee’, the columns - EmpID, Employee Name, Employee DoB, Employee Phone No, are known as Fields. The rows, which have the details, are the records and this can be any number.
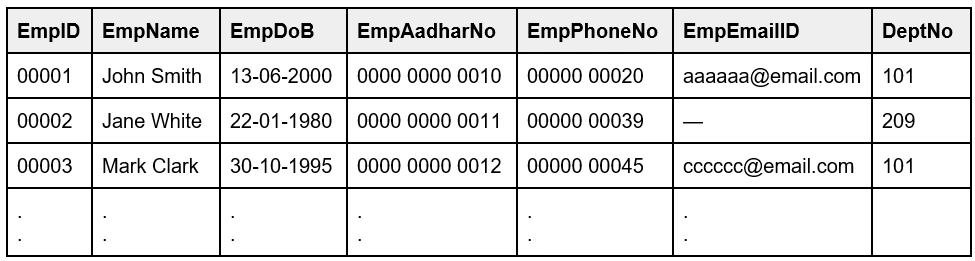
6. What are the different types of Tables in SQL?
The table types in SQL are as follows:
- Partitioned tables
- Temporary tables
- System tables
- Wide tables
7. What is a tuple?
A tuple is a single table row that represents a single record of a relation, of that table. A tuple contains all the data of a single record.
For example, the highlighted row of the EmpID 00002 is a tuple.

8. What are Temporary Tables?
Temporary Tables store data only during the current session, and not beyond that. This table will be deleted once the session is over. This table acts exactly like a permanent table in which the user can create, read, modify, update, delete, retrieve data. The Temporary Tables consist of two types - Local and Global.
Local temporary tables are visible to the user who created them, and will be dropped once the user disconnects from the server. The global one is visible to all the users and will be dropped only when all the users get disconnected.
9. What is a Super Key?
A Super Key is a group of single or multiple keys that identifies records in a table, uniquely. Sometimes, the keys independently do not identify the record, but the combination of the keys, when grouped, can identify records in a table. Primary Key, Unique Key, Alternate Key, Candidate Key are subsets of Super Key.
For example, the EmpID is a Super Key of the table, but there can be other Super Keys. The EmpID, EmpAadharNo, EmpPhoneNo, EmpEmailID, can all be Super Keys as they can uniquely identify a record in the table.

10. What is a Primary Key?
Primary Key: A Primary Key is a combination of one or more fields of a table that uniquely identify records in a database. There can be only one primary key for a table, and the table that has the primary key is called the parent table. The Primary Key values cannot be null or empty.
For example, the EmpID and EmpAadharNo can be the Primary Keys, as they are unique, and cannot accept NULL values. Out of these, EmpID is selected as the Primary Key.
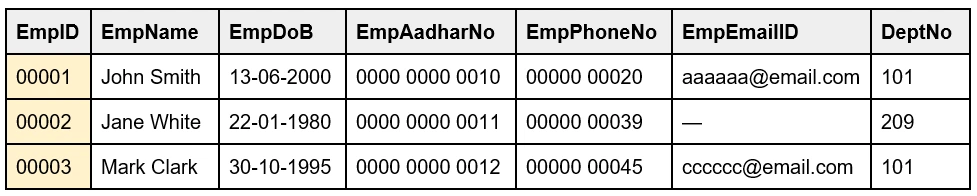
11. Alternate Key can be a Primary Key. Justify the statement.
An Alternate Key is a key that can work as a Primary Key, but is currently not the Primary Key. An Alternate Key is a column or group of columns in a table that uniquely identifies records in that table. Every table has many choices for a Primary Key, out of which only one column is set as Primary Key. The other keys which are not selected as the Primary Key are called Alternate Keys of that table.
For example, the EmpID and EmpAadharNo can be Primary Keys, but since EmpID is selected as Primary Key, me EmpAadharNo is an Alternate Key.
Table: Employee

12. What is a Candidate key?
A Candidate key is a set of one or more attributes to identify records in a table. It is a subset of Super key and is unique. There can be one or multiple Candidate keys in a table and each candidate key can work as a Primary key. Candidate keys include Primary key and Alternate keys.
For example, EmpID and EmpAadharNo can work independently as Primary keys as they uniquely identify records in a table.
Table: Employee

13. What is a Unique Key?
A Unique Key is a single or combination of columns (fields) of a table that uniquely identifies each record in the database, ensuring that the column cannot store duplicate values (only unique values). This provides uniqueness for the fields or the set of fields. The Unique Key is like the Primary key as it can not have duplicate values but unlike Primary key, it can accept only one null value.
For example, the EmpID, EmpAadharNo, EmpPhoneNo, EmpEmailID can be Unique keys as they are unique without any duplication. But the EmpID and EmpAadharNo cannot accept any Null values. The EmpPhoneNo and EmpEmailID can have only one null value like the empty EmpEmailID record for the EmpID 00002.
Table: Employee

14. Can the Composite key act as Primary key?
A Composite key is a combination of two or more fields in a table helps to identify a record in the table. The Composite key can identify records only in combination and a single column in the Composite key cannot identify the records independently. Each field may not be unique on its own. The Composite key, the combination of fields, can act as Primary key as it uniquely identifies records, and can be a combination of Candidate keys.
For example, the EmpName, EmpDoB and DeptNo together, as a combination, can identify a record in a table and can act as Primary key (only in combination).
Table: Employee

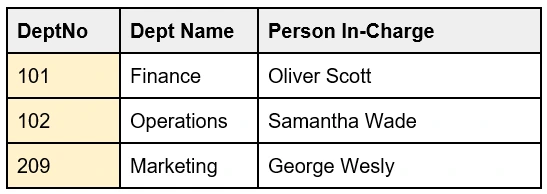
15. Why Foreign key is called Referencing key?
A Foreign key is also known as a Referencing key as this key refers to a key in another table. It is one column or combination of columns of a table that links to the Primary key of another table. This key connects two tables. A table can have more than one foreign key, and the table that has the foreign key is the child table and the table that has the Primary key is the Parent table.
For example, in the table 'Employee', the DeptNo is the Foreign key as it refers to the Primary key of another table 'Department' ie., the DeptNo.
Table: Employee

Table: Department
16. Explain the difference between a Primary and Unique key?
| Primary Key in SQL | Unique Key in SQL |
| Cannot be NULL. | May have one NULL value. |
| There can be only one Primary key per table. | A table may have multiple Unique keys. |
| Creates a clustered index. | Created a non-clustered index. |
17. What is data independence in SQL? Explain its types.
Data independence is a property that lets us change the schema of a database at one level without causing alterations in the higher level of the schema.
There are two types of data independence, frequently asked in SQL interview questions:
- Physical Data Independence - It means that any change in the physical data storage will not affect the conceptual schema of the database.
Example: changing the location of the database in memory
- Logical Data Independence - It means that any change in the conceptual schema will not affect external views.
Example: Merging two records
Read more about data independence in SQL here.
18. Explain the advantages and disadvantages of views in SQL?
Advantages of views:
- Views can be used to restrict the visibility of data columns to users.
- They do not actually use physical storage to store data. They can be understood as virtual tables.
- Views can provide access permissions to users for executing various commands.
Disadvantages of views:
- When a table is dropped, the view gets deactivated. In such a case, we cannot use the view anymore.
- DML commands cannot be used on views because they are not stored physically in storage.
- Views on large database tables occupy more memory space of the system.
- The execution speed of view is slow because it works on data retrieval queries.

Intermediate SQL Interview Questions and Answers
19. What are DQL, DCL, TCL?
- DQL: Data Query Language commands get/fetch data from a database, so that operations can be performed on the fetched data. The DQL command is SELECT.
- DCL: Data Control Language commands give users the rights, permissions, and other controls of the database. The DCL commands are GRANT, REVOKE.
- TCL: Transaction Control Language commands are a set of commands that manages the transactions that take place within a database. The TCL commands are COMMIT, ROLLBACK, SAVEPOINT.
20. What are the differences between DDL and DML?
| Data Definition Language (DDL) | Data Manipulation Language (DML) |
| DDL commands are used to create, modify, delete database structures, not the data. These commands define the database structure. | DML commands used for the manipulation of data of a database. These commands modify the data by inserting, modifying, deleting records, and perform all kinds of changes in a database. |
| DDL commands make permanent changes, and there is no option of roll back. | DML commands do not make permanent changes, so there is a possibility of roll back. |
| DDL commands work on the entire database, not the data, and this affects the database as a whole. | DML commands work on the records in a database, so this affects one or more records based on the query. |
| DDL commands are not used by a common user regularly, as they just have to access data. | DML commands are regularly used by common users to access data. |
Some of the DDL commands are,
|
Some of the DML commands are,
|
21. Compare local variables and global variables?
| Local Variables | Global Variables |
| Declared and used inside a function | Declared outside of a function |
| Exists only within that function and are not used or referred from outside the function | Exists outside of the function and are referred outside the function |
| Exists only till the execution of the function | Exists till the execution of the entire program |
| Stored in stack memory | Stored in fixed memory |
| Cleaned up automatically | Do not get cleaned up automatically |
22. What are Constraints?
Constraints are rules that control the data of a column. The conditions or the limitations on the data of a column ensures the reliability and accuracy of the field.
There are two types of constraints - Column level and Table level.
The column level constraints are applicable to the columns and the table level constraints are applicable to the entire table. Some of the SQL constraints are NOT NULL, UNIQUE, PRIMARY KEY, FOREIGN KEY, CHECK, DEFAULT, INDEX.
23. What is an Index?
Indexes are used to speed up the retrieval of data from a database by locating the data quickly without having to check every row in the table. The indexes are not visible to the user, as the purpose of the index is to reduce the duration of time taken to retrieve data.
24. What is a JOIN operation?
A JOIN clause is an operation used to combine rows from more than one table, only when there is a logical relationship between those tables.
Different types of SQL JOINs are as follows.

- Inner Join - Retrieves only the values that have matching column values with the other table
- Outer Join
- Left Join - Retrieves all records from the Left table mentioned in the FROM clause, and the matched records from the Right table
- Right Join - Retrieves all records from the Right table, in addition to the matched records from the Left table
- Full Join - Retrieves all records from both the tables, including the non-matching values
25. Explain briefly about NOT NULL, UNIQUE, CHECK, DEFAULT.
- NOT NULL - This constraint is to ensure that the column cannot store NULL value.
- UNIQUE - This constraint accepts only unique values, preventing duplicate values in a column.
- CHECK - This constraint ensures that the values in the column meet specific conditions.
- DEFAULT - It specifies a default value for the fields of a column when no value is specified for the fields.
26. Name the operators in SQL.
- Arithmetic Operators
- Bitwise Operators
- Comparison Operators
- Compound Operators
- Logical Operators
27. What are Stored Procedures?
The stored procedure is a set of statements that can be saved, and this code can be reused again and again, whenever there is a requirement. This function is compiled only once and can be called any time during execution of the program.
28. What is an Aggregate Function?
An Aggregate Function calculates on multiple values of a column and returns a single value. Other than the COUNT(), this function ignores NULL value. Various types of Aggregate function are as follows.
- AVG() – returns the average of a set
- COUNT() – returns the number of items in a set
- MAX() – returns the maximum value in a set
- MIN() – returns the minimum value in a set
- SUM() – returns the sum of all or distinct values in a set
29. Name a few common clauses used with the SELECT query.
- WHERE - This clause is used to filter records based on the required criteria.
- ORDER BY - This clause is used to sort data in descending (DESC) order or in ascending (ASC) order. The ascending order is the default order.
- GROUP BY - This clause is used to group rows that have identical data into summary rows, by one or more columns. This clause is used with Aggregate functions mostly.
- HAVING - This clause is used with the GROUP BY clause to filter records like WHERE. But, WHERE cannot be used by Aggregate functions.
30. What is a Scalar Function?
Scalar function is a built-in function and the output returned by this function will be a single value, when it is invoked. This function accepts parameters for single value or multiple values. Some of the scalar functions are:
- UCASE() - To change the case of the string to Upper case characters
- LCASE() - To change the case of the string to Lowercase characters
- MID() - To extract a specific portion (substring) from a string
- LENGTH() - To return the length of the string in a column
- ROUND() - To round a number in a column to the number of decimals specified
- NOW() - To return the system's current date and time
- FORMAT() - To format how a column is to be displayed
31. What are the data types in SQL?
- String data types: String data type allows to store strings in a record of a column. These strings can be characters, texts, numerals, symbols. The data type can be either fixed or variable. The list of datatypes that are under the string are char(n), varchar(n), varchar(max), text, nchar, nvarchar, ntext, nvarchar(max), binary(n), varbinary, varbinary(max), image.
- Numeric data type: Numeric data types are used to store only the numeric values. The list of datatypes under the numeric data type are bit, tinyint, smallint, int, bigint, decimal(p,s), numeric(p,s), smallmoney, money, float(n), real.
- Date and Time data type: Date and Time data types are used to store date and time. The list of datatypes under this data type are datetime, datetime2, smalldatetime, date, time, datetimeoffset, timestamp.
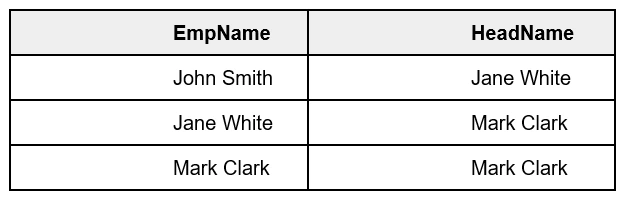
32. What is a Self Join and a Cross Join?
Self Join:
The Self join, a type of inner join, is used to join a table to itself. For this join, a comparison between two columns is done. In which, one column acts as primary key and another column that stores values can be matched with the primary key column.
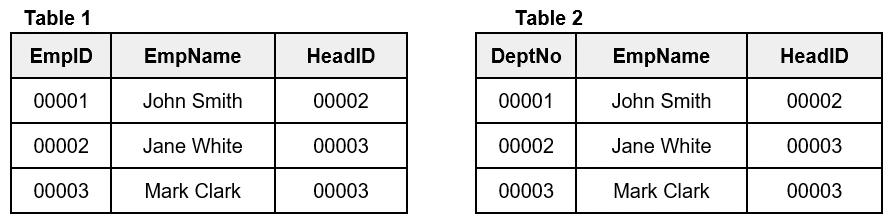
Self Join
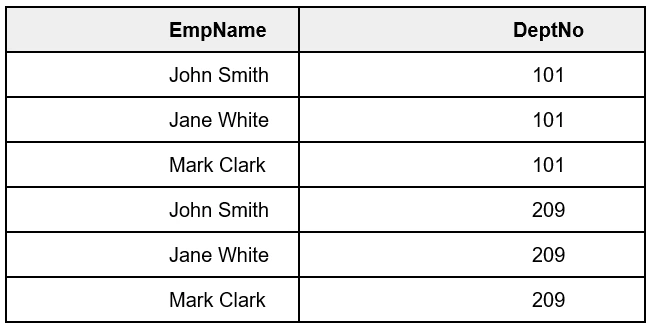
Cross Join:
A cross join is used to retrieve the cross product of two individual tables. This join combines each row of the first table to each row of the second table.
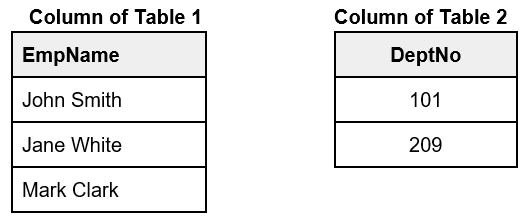
Cross Join
33. Explain cursors and their types in SQL.
Cursors are temporary work areas in the memory which store the data retrieved from the SQL query for manipulation or traversing through it. They are database objects which store the rows returned by the query and point to a single row at a time.
There are two types of cursors that you should know for SQL interview questions:
- Implicit cursor: These are the default cursors of SQL used for internal processing. They are used whenever a DML command - insert, delete, update, etc. are executed.
- Explicit cursor: These are explicitly created by the user whenever required for fetching data row by row. E.g. creating a SQL block
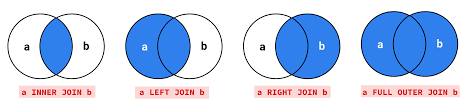
34. Explain different Joins in SQL.
SQL Joins are used to combine two or more tables based on a related column.
Different types of SQL Joins are:
- Inner Join - Returns all rows from both the tables where the join condition is satisfied.
- Left Join - Returns all rows from the left side table and rows which satisfy the join condition from the right side table.
- Right Join - Returns all rows from the right side table and rows which satisfy the join condition from the left side table.
- Full Outer Join - Returns all rows where the join condition is satisfied from both tables.
35. Explain the importance of database partitioning in SQL.
In a database, table, index, or indexed table can be partitioned into smaller pieces called partitions. This process of subdividing is called database partitioning. Importance of database partitioning to know for SQL interview questions practice are:
- Better performance of the queries because only a partition needs to be checked and not the whole table.
- Administrators can manage smaller chunks of data more effectively.
- Maintenance is easier on the small partitions than the whole large table.
- For a database table, if one partition is unavailable due to some issue and the rest of the partitions are available, this will ensure better database availability for query execution.
36. Explain the difference between WHERE and HAVING clauses in SQL.
| WHERE Clauses | HAVING Clauses |
| Selects rows based on the conditions provided. | Applies to aggregated rows and it is a column operation. |
| GROUP BY is executed after the WHERE clause in the query. | GROUP BY is executed before the HAVING clause in the query. |
| Used with SELECT, DELETE, and UPDATE. | Cannot be used without a SELECT clause. |
| Aggregate functions can not be used. | Aggregate functions like min, max, avg, etc. are used. |
Advanced SQL Interview Questions and Answers
37. List down some of the Logical Operators.
- TRUE if all of the subquery values meet the condition (ALL)
- TRUE if all the conditions separated by AND is TRUE (AND)
- TRUE if any of the subquery values meet the condition (ANY)
- TRUE if the operand is within the range of comparisons (BETWEEN)
- TRUE if the subquery returns one or more records (EXISTS)
- TRUE if the operand is equal to one of a list of expressions (IN)
- TRUE if the operand matches a pattern (LIKE)
- Displays a record if the condition(s) is NOT TRUE (NOT)
- TRUE if any of the conditions separated by OR is TRUE (OR)
- TRUE if any of the subquery values meet the condition (SOME)
38. Explain differences between DROP, DELETE, and TRUNCATE commands.
- Drop command in SQL is used to delete the entire schema of the table permanently.
- Delete command in SQL is used to delete the rows of the data table.
- Truncate command in SQL is used to delete the entire table and free up the memory space.
Below table shows the differences between DROP, DELETE and TRUNCATE command in SQL:
| DROP command in SQL | DELETE command in SQL | TRUNCATE command in SQL |
| DDL command | DML command | DDL command |
| Cannot be rolled back | It can be rolled back | Cannot be rolled back |
| Drops the whole table schema, triggers, data, and indexes permanently | Deletes all rows or one by one as per the query | Deletes all rows in one go |
| Does not use the WHERE clause | Uses WHERE clause | Does not use the WHERE clause |
| Faster than DELETE slower than TRUNCATE | Slowest of all three | Fastest among three |
39. List the syntaxes of the following commands - WHERE, DELETE, ORDER BY.
WHERE Syntax:
```sql
SELECT column1, column2, ...
FROM table_name
WHERE condition;
```
Example:
```sql
SELECT * FROM Employee
WHERE DeptNo='101';
```
DELETE Syntax:
```sql
DELETE FROM table_name WHERE condition;
```
Example:
```sql
DELETE FROM Employee WHERE EmpID='00003';
```
ORDER BY Syntax:
```sql
SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;
```
Example:
```sql
SELECT * FROM Employee
ORDER BY EmpName;
```
40. Write the code to select the highest salary and lowest salary in an Employee database.
Min(): Returns smallest value of the selected column
Syntax:
```sql
SELECT MIN(column_name)
FROM table_name
WHERE condition;
```
Example:
```sql
SELECT MIN(Salary)
FROM EmployeeSal;
```
Max(): Returns largest value of the selected column
Syntax:
```sql
SELECT MAX(column_name)
FROM table_name
WHERE condition;
```
Example:
```sql
SELECT MAX(Salary)
FROM EmployeeSal;
```
41. What is the difference between Clustered Index and Non-clustered Index?
| CLUSTERED INDEX | NON-CLUSTERED INDEX |
| Data is physically stored in a table and sorted alphabetically in the table | Physical data doesn’t get sorted inside the table. Non-clustered Index is stored in one place and data stored in another place. |
| One clustered Index per table | More than one non-clustered index per table |
| Faster data access than non-clustered index | Slower data access than clustered index |
| Needs less memory for operation execution | Needs more memory for operation execution |
| Does not require additional disk space | Requires additional disk space |
| Stores data on the disk | Does not store data on disk |
| Stores data pages in the leaf nodes of the index | Does not store data pages in the leaf nodes of the index |
42. Give an example of auto increment for the Employee ID.
Auto-increment generates numbers automatically when a new row is created in a table, incrementally. The numbers are incremental. By default, the starting value is 1, and will increment by 1, for every new record.
The EmpID for the records of the table ‘Employee’, can be a primary key and can be generated automatically using Auto-Increment.
```sql
CREATE TABLE Employee (
/* Starting value is 1
Increment by 1 */
EmpID int IDENTITY(1,1) PRIMARY KEY,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int
);
```
43. Give examples for the SELECT command.
a. Select all the records from a table named "Employee" where the value of the column "EmpName" starts with an "a"
```sql
SELECT * FROM Persons WHERE FirstName LIKE 'a%'
```
b. Select all the records from a table named "Employee" where the "EmpFirstName" is alphabetically between (and including) "John" and "Mark"
```sql
SELECT * FROM Employee WHERE EmpFirstName BETWEEN 'John' AND 'Mark'
```
c. Return all the records from a table named "Employee" sorted descending by "EmpFirstName".
```sql
SELECT * FROM Employee ORDER BY EmpFirstName DESC
```
44. Give examples for the following.
a. Insert "Jane" as the "EmpFirstName" in the "Employee" table.
```sql
INSERT INTO Employee (EmpFirstName) VALUES ('Jane')
```
b. Delete the records where the "EmpFirstName" is "Mark" in the Employee Table.
```sql
DELETE FROM Employee WHERE EmpFirstName = 'Mark'
```
c. Change "Jane" into "Alicia" in the "EmpFirstName" column in the Employee table.
```sql
UPDATE Employee SET EmpFirstName='Alicia' WHERE EmpFirstName='Jane'
```
45. Explain with example about SELECT DISTINCT
In a column, there are chances that the values are repeated (duplicate values). The DISTINCT allows only the different values (without duplication).
Syntax:
```sql
SELECT DISTINCT column1, column2, ...
FROM table_name;
```
Example:
```sql
SELECT DISTINCT DeptNo FROM Employee;
```
46. Give examples of the operators - AND, OR, NOT
AND: Displays a record only if all the conditions are TRUE
Syntax:
```sql
SELECT column1, column2, ...
FROM table_name
WHERE condition1 AND condition2 AND condition3 ...;
```
Example:
```sql
SELECT * FROM Employee
WHERE EmpName='John Smith' AND DeptNo='101';
```
OR: Displays a record only if any of the conditions are TRUE
Syntax:
```sql
SELECT column1, column2, ...
FROM table_name
WHERE condition1 OR condition2 OR condition3 ...;
```
Example:
```sql
SELECT * FROM Employee
WHERE DeptNo='101' OR DeptNo='209';
```
NOT: Displays a record only if the condition(s) are NOT TRUE
Syntax:
```sql
SELECT column1, column2, ...
FROM table_name
WHERE NOT condition;
```
Example:
```sql
SELECT * FROM Employee
WHERE NOT DeptNo='101';
```
47. Give the syntax for Inner Join and Full Outer Join.
Inner Join Syntax:
```sql
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column_name;
```
Full Outer Join Syntax:
```sql
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name = table2.column_name
WHERE condition;
```
48. What is SQL Hosting?
SQL Hosting refers to web hosting, having SQL database backend for the website. The web server has access to the database, able to store, update and retrieve data. For example, for a login page, the user name and password are created, updated, verified, and deleted from the database of the website.
The most common SQL hosting databases are as follows.
- MS SQL Server
- Oracle
- MySQL
- MS Access
49. Explain about SQL Injection.
SQL Injection is a web hacking technique for backend data manipulation that can destroy the database. In this technique, malicious SQL code is injected, and if successful, the hacker can view, retrieve, modify, delete data which are not accessible to the attacker, normally. This data can be sensitive, personal data of customers.
For example, this injection occurs when the hacker enters a malicious SQL statement instead of user name/id and these statements are run on the database unknowingly.
50. What is ORDER BY RANDOM and what is the purpose of it?
This function is used to randomly order a record or a row from a database. This is used to fetch records unsystematically This fetching of data does not follow any certain order. This will be used in retrieving random information to the user, like articles, posts in blogs, random info/quote, etc.,
The basic syntax is as follows.
```sql
SELECT * FROM TableName ORDER BY RAND() LIMIT1;
```
51. Write the syntax and example code for SQL CREATE TABLE.
The CREATE TABLE statement is used to create a new table in a database.
Syntax:
```sql
CREATE TABLE table_name (
/* 'column' 'specifies the names of the columns of the table.
'datatype' specifies the type of data the column can hold. */
column1 datatype,
column2 datatype,
column3 datatype,
....
);
```
Example:
```sql
CREATE TABLE Employee (
EmpID int,
EmpFirstName varchar(255),
EmpLastName varchar(255),
);
```
RDBMS Interview Questions and Answers
We cannot imagine any application will work without the support of databases. Databases have traversed a long way from flat files to hierarchical models to RDBMS and now NoSQL based databases. Today Big data and Business Intelligence(BI) work solely on NoSQL databases. This depicts the importance of a database based career in the technical field.
52. What are the different features of RDBMS?
Below are the important features of RDBMS which make it reliable and consistent:
- Structured storage: Data is stored in structured data tables which makes data retrieval easier.
- Unique identification: Data is stored in rows and columns, with a unique primary key. This makes it easy to identify and retrieve the data uniquely.
- Indexes: RDBMS supports the indexing of data for quick data retrieval.
- Views: Virtual tables or views help in hiding sensitive data. Different users may have different views as per their role access.
- Concurrent users: Multiple users can have the access to the database and they may access the RDBMS concurrently.
53. What is an E-R model in RDBMS?
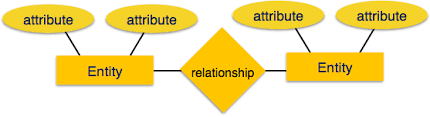
The E-R model or Entity-Relationship model is a high-level data model. It defines the relationship between the different entities in RDBMS. There are three components in an E-R model:
- Entity - Represents an object(person, place, class, etc.) It is denoted by a rectangle in the E-R diagram.
- Attributes - Represents the properties of an entity. It is denoted by an eclipse in the E-R diagram.
- Relationship - Represents the relationship between the entities. It is denoted by a diamond in the E-R diagram.
Detailed tutorial here.
54. What are the levels of abstraction in RDBMS?
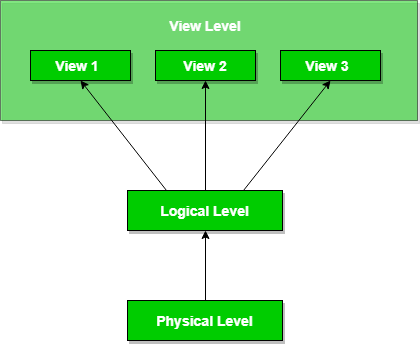
There are three levels of abstraction in RDBMS:
- Physical level: It is the lowest level of abstraction which defines the actual physical storage of data in the memory. Here we deal with the memory size, data accessing mechanisms, hashing, etc.
- Logical level: It is the middle level of the abstraction in RDBMS. Here we deal with the tables, attributes of the objects, and relationships between the entities.
- View level: This is the highest level of abstraction present in RDBMS. Here we define the interaction of users with the database. Different users have access to different views of the same database according to the requirement.
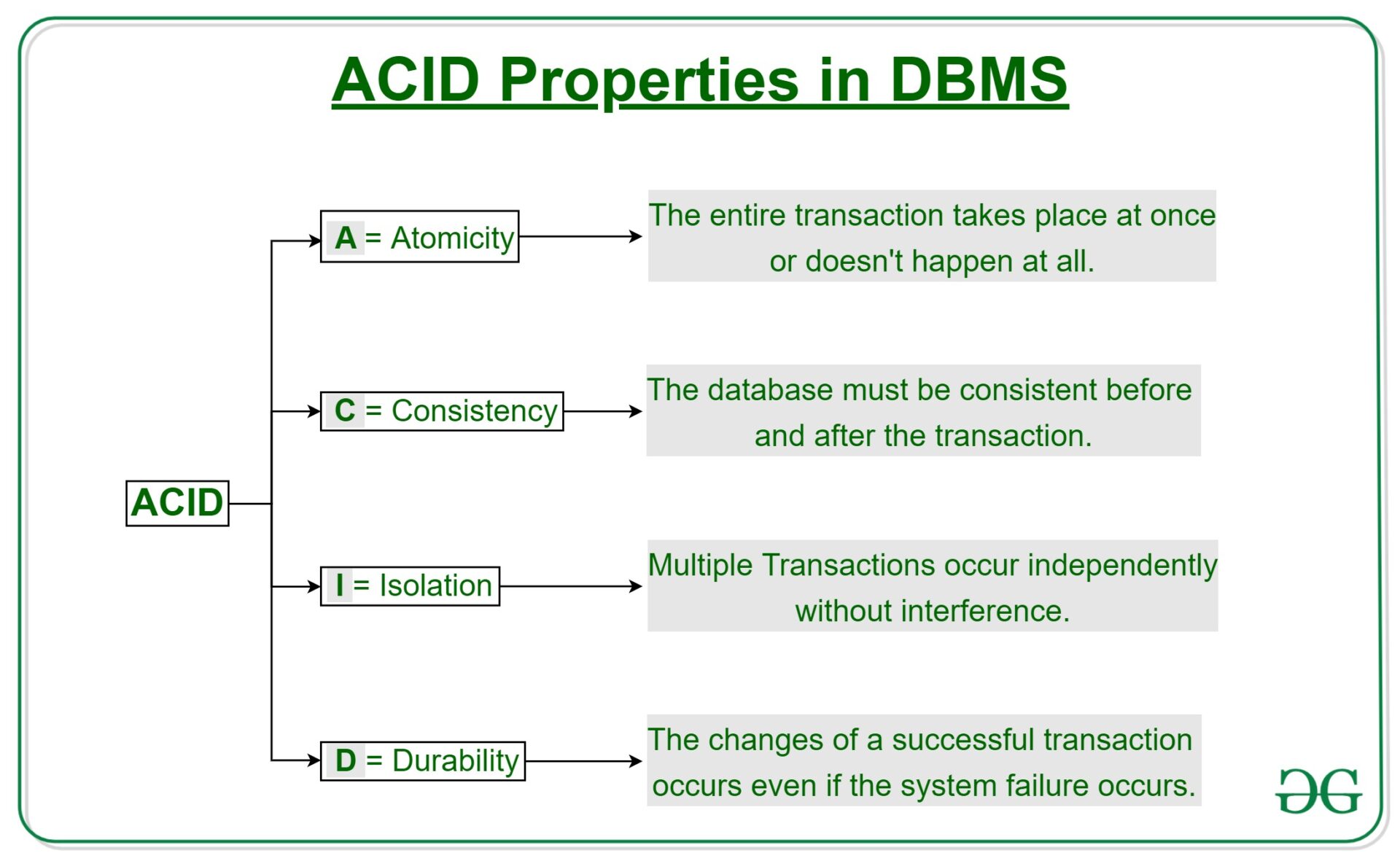
55. What are ACID properties in DBMS?
The ACID properties in DBMS are its backbone, and these properties provide the necessary rules which the RDBMS transactions should follow.
- Atomicity: Each database transaction is a single unit and it should be processed completely and not partially. Hence, a database transaction should either complete or not execute at all. There is no middle state in the case of RDBMS.
- Consistency: Database maintains correctness and integrity after the execution of a transaction. Hence, only valid data according to the rules and constraints of the database should get written in the database.
- Isolation: Database transactions may execute concurrently without interfering with the other. Additionally, the transactions should not violate the stability and consistency of the database.
- Durability: When a database transaction is executed completely, then in case of system failure, it will maintain the consistency of the database. In such cases, the transactions will remain present in the database.
56. What is normalisation and its different forms?
Normalisation is a process of organising the data in the RDBMS in such a way that it eliminates redundancy in relations and a set of relations. Additionally, when we use an update, insert, or delete on redundant data then it causes abnormalities in the database. Hence, we should reduce the data into normal forms to remove these anomalies.
The most popular normal forms are:
- 1NF - First Normal Form states that every attribute(represented by column) of the database table should be atomic. Therefore, in 1NF the attribute should not contain a composite value.
- 2NF - Second Normal Form states that the table should be in 1NF. In addition, all non-key attributes should be fully functionally dependent on the primary key.
- 3NF - Third Normal Form, states that first, the table should be in 2NF. Secondly, there should be no transition dependency.
- BCNF - Boyce-Codd Normal Form states that first, a table should be in 3NF. Secondly, for every functional dependency A->B, A should be a super key of the table.
57. List and explain the different types of keys in RDBMS?
We use a database key to uniquely identify a row or record in a database table. Where a key can be composed of a single attribute or a set of attributes which help us to uniquely identify a row.
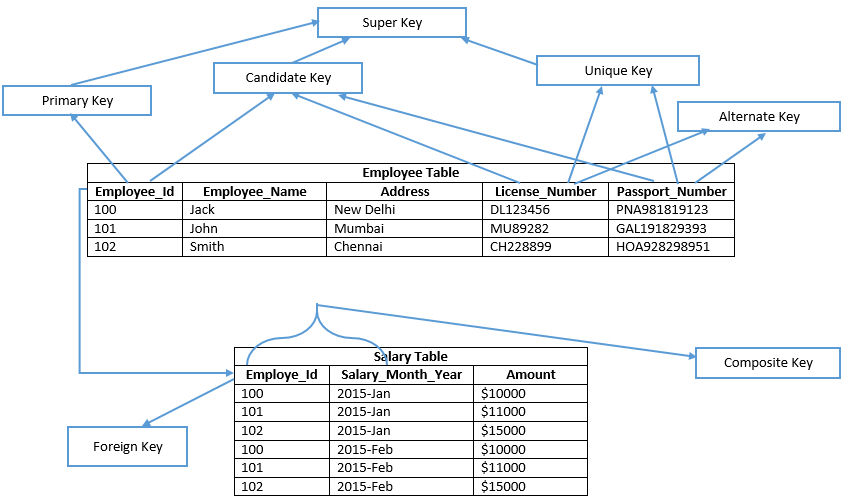
Different types of keys in RDBMS are-
- Super key: It is a group of single/multiple keys to identify a row uniquely. It may also have some attributes which are not needed to uniquely identify rows.
- Candidate key: It is a super key but does not have additional attributes which are not needed to uniquely identify the rows. A table can have multiple candidate keys.
- Primary key: It is selected from the candidate keys of a table. A table can have only one primary key to uniquely identify rows.
- Composite key: Two or more attributes are combined together to uniquely identify the rows. These attributes individually cannot identify rows uniquely.
- Foreign key: It is a column which shows a relationship with the primary key of another table. A table can have multiple foreign keys.
- Alternate key: A key which is not a primary key but can be used to uniquely identify rows in the table. A table can have one or more choices for the primary key and we can choose one out of them as the primary key. Hence, the rest of the keys among the choices are alternate keys.
58. What are the different data models in RDBMS?
The common data models in RDBMS are:
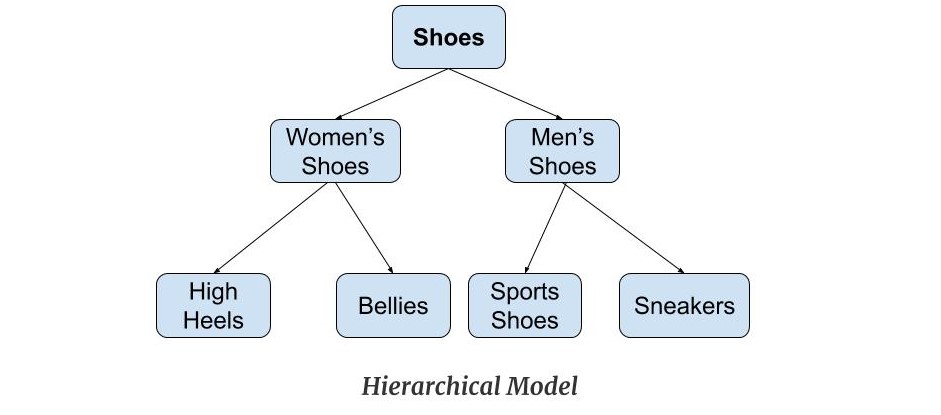
Hierarchical model- Data is present in a tree structure hierarchy. There is a single root and other data are linked to the root node. It maintains a parent-child relationship between the nodes of the tree.
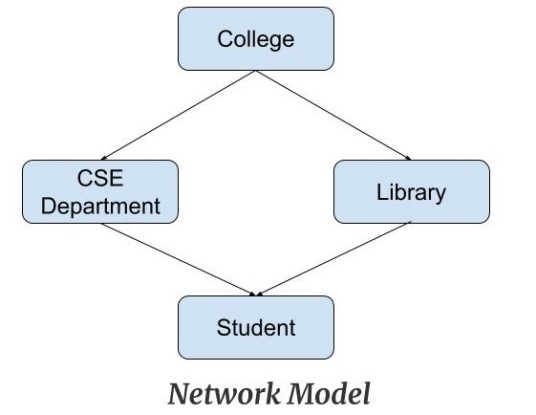
Network model - The network model is an extended version of the hierarchical model where a node can have more than one parent.
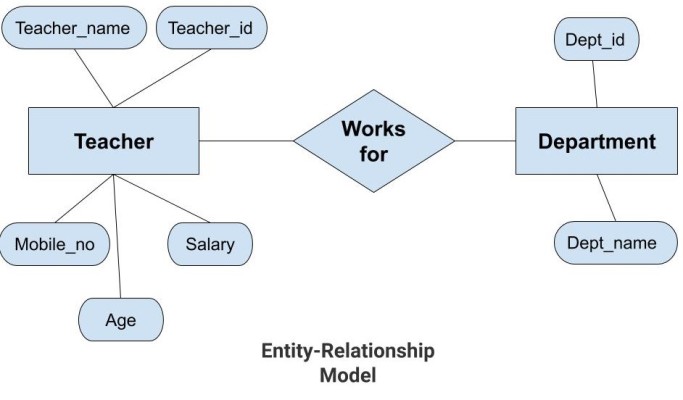
Entity-Relationship model - It has an object defined as an entity and the properties defined as attributes. The entities have a relationship between them denoted by a diamond in the diagram.
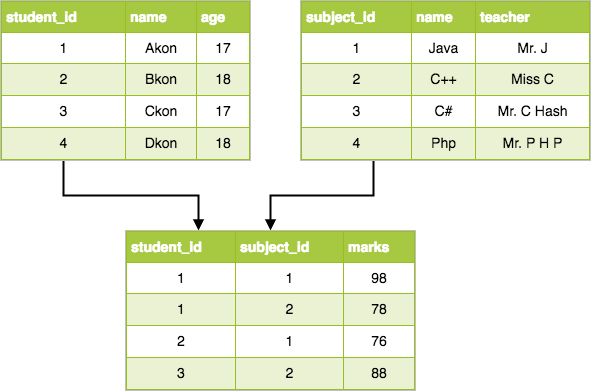
Relational model - The data is stored in a two-dimensional table with rows and columns.
59. Explain the differences between vertical and horizontal scaling of databases.
Vertical and horizontal scaling are two types of database scaling. Scaling is done when the data load increases on the database and then we need to choose any one of the scaling types.
| Horizontal Scaling databases. | Vertical Scaling Databases. |
| Involves multiple machines. | Involves a single machine. |
| The data resides on multiple nodes wherein data is partitioned and distributed among different nodes. | The data resides on a single node and the load is distributed by scaling RAM and CPU etc. of the machine. |
| Also known as scaling-out. | Also known as scaling-up. |
Backend Technology Interview Questions
C Programming Language Interview Questions | PHP Interview Questions | .NET Core Interview Questions | NumPy Interview Questions | API Interview Questions | FastAPI Python Web Framework | Java Exception Handling Interview Questions | OOPs Interview Questions and Answers | Java Collections Interview Questions | System Design Interview Questions | Data Structure Concepts | Node.js Interview Questions | Django Interview Questions | React Interview Questions | Microservices Interview Questions | Key Backend Development Skills | Data Science Interview Questions | Python Interview Questions | Java Spring Framework Interview Questions | Spring Boot Interview Questions.
Database Interview Questions
PostgreSQL Interview Questions | MongoDB Interview Questions | MySQL Interview Questions | DBMS Interview Questions
Interview Preparation Tips
Strength and Weakness Interview Questions | I Accepted a Job Offer But Got Another Interview | Preparation Tips For the Virtual Technical Interview | 7 Tips to Improve Your GitHub Profile to Land a Job | Software Engineer Career Opportunities in Singapore | What can you expect during a whiteboard interview | How To Write A Resignation Letter | Recommendation Letter Templates and Tips.
Quick Links
Practice Skills | Best Tech Recruitment Agency in Singapore, India | Graduate Hiring | HackerTrail Litmus | Scout - Sourcing Top Tech Talent in ONE Minute | About HackerTrail | Careers | Job Openings.


