

Databases, Data Lakes, and Data Warehouses Explained
Big data is ruling the technology world today. To stay ahead in the competition, companies are leveraging their data to derive business value from it. However, a successful data analytics strategy depends on which technology one uses for storing, searching, analyzing, and reporting data.
The three of the common data storage are databases, data warehouses and data lakes. But the question still remains, which one of these should a company choose?
Therefore, it is important to understand what is a data lake, a database and a data warehouse? How do they differ from each other and how do they work? Which should a business choose based on its current data strategy, business goals, and infrastructure?
As the first step towards this decision making, let us understand the basic concepts.
1. What is a database?
2. What is a data warehouse?
3. What is a data lake?
4. Comparison between Databases vs Data Warehouse vs Data Lakes
5. How to select the right data storage for your requirements?
1. What is a database?
The database is a highly structured form of data storage where the data is stored in known formats and types, making it easier to access and manage.
The widely used databases are a relational database or SQL database, and a non-relational database or NoSQL. The latest addition is the cloud database which is designed to run on cloud applications.
The database is ideal for use cases like report creation for financial and sales data, analysis for smaller datasets, auditing of data entry, automating business processes and so on. Compatibility is another factor to consider when a requirement arises for a database to work with various programs. This may include converting data to different formats, thereby making it less 'agile' than other data storage types.
Some examples of common databases are:
PostgreSQL, MySQL, MongoDB, Microsoft Azure SQL DB, and Elasticsearch.

2. What is a data warehouse?
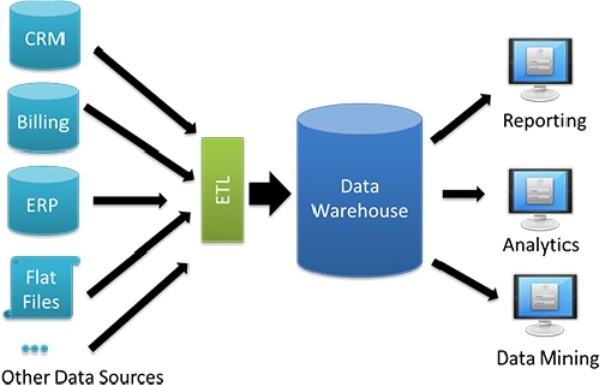
A data warehouse is a data management system that derives data from several storages and operational systems within an organisation and acts as a single point of access. It is designed for the enablement and support of data analytics and business intelligence. It can be thought of as a large central repository that provides users with current and historical data that supports decision making.
Due to these features, it can be called an enterprise’s single point of truth’. An important component of a data warehouse is an ETL (extract, transform, load) solution that helps in preparing data for analysis. This analysed data is then further used for analytics, reporting or data mining.
Some of the popular data warehouses offered are Snowflake, Yellowbrick and Teradata.

3. What is a data lake?
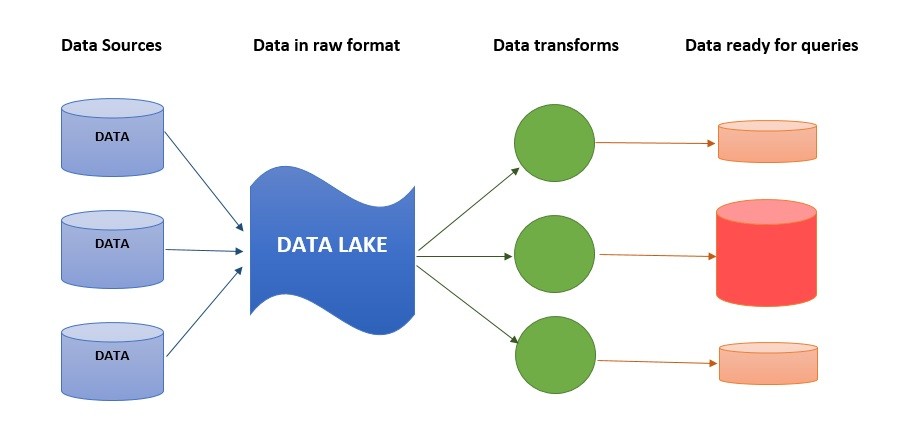
A data lake is a central location that stores a huge amount of disparate and unstructured data in its raw format until it is later required for processing. The raw data, captured from various sources like mobile apps, IoT devices, social media, business applications, is structured and its data format is derived at the time of analysis. A data lake is usually used to gather insight for data science research and testing, which is why it is also known as 'for machines' data storage type.
Hadoop, Amazon S3 and Azure data lake are the most commonly used ones.
4. Comparison between Databases vs Data Warehouse vs Data Lakes
Now let’s do a quick comparison between these three storage types based on the 6 key areas:
| Key Area | Database | Data Warehouse | Data Lake |
| Data types supported | Stores only structured data | Stores only structured data | Stores data in its raw format, whether structured, semi-structured or unstructured |
| Processing | Follows schema on write, i.e., it requires a data model before loading any data | They also follow schema on write | Accepts data in its raw form during storage. It follows schema-on-read, i.e., create the schema when you require data for usage |
| Storage costs | Flexible options ranging from cheap storage to expensive ones | A data warehouse has a low storage cost but high operational and maintenance cost | Data lake is highly accessible and designed to support low storage and operational cost |
| Agility | Fixed structure makes it less agile to configure | Lacks agility and flexibility | Lack of structure makes it highly agile and flexible. Easy to configure data models, queries and applications |
| Security | Databases are highly vulnerable to hackers as they are generally on the same server or same network as the application or website itself | In a data warehouse, the data sources are known which enables it to follow a sandbox approach and define user access, making it highly secure | The biggest security challenge for the data lake is the lack of data quality which could result in a corrupted or a malware file getting stored in the data lake |
5. How to select the right data storage for your requirements?
In order to make the right storage selection, you need to understand the key areas versus your requirements.
- Data sources and types: One of the deciding factors in selecting data storage is the number of data sources you have and the data type or formats in those sources. Another point to consider is whether their structure or schema is known ahead of time and is it consistent throughout.
- Data processing requirements: While selecting the data storage, one needs to keep in mind the type of data model included in the data management strategy. It is also crucial to understand when the data model or schema is defined; whether schema-on-read or schema-on-write. Unlike Data lakes, Databases and Data Warehouses require ETL processes to transform raw data into a pre-determined structure.
- Budget constraints: The business value that big data provides to enterprises is generally represented in their data management budgets. With data growing in terms of volume and velocity, the cost of storing it also increases. Thus, the storage option a company selects largely depends on its cost constraints. For instance, while data lakes are highly efficient, data warehouses take more storage for processing and are therefore costly. Databases, on the other hand, can scale up and down according to the business requirements
- Technology & data ecosystem: Organizations differ in their attitudes toward open source and proprietary software, as well as the communities that support them. Because of the broad deployment of Hadoop and the surge in unstructured data from multiple systems across the firm, as well as real-time data streams, data lakes have become increasingly popular. Another aspect of technology to ponder is the system's accessibility and fidelity with the change in data sources and structures. For example, it is expensive to update a relational database and data warehouse, however, updating a data lake is straightforward.
- Data usage and users: Who uses the data and for what purpose is another factor that helps in deciding which data storage to select.
The “database vs data warehouse vs data lake” debate has likely just begun. The differences in their structure, process, use, and agility make each of the data storage unique. However, despite the differences, these three data storage types share the same goal i.e. centralizing data into a single location that can be further used for uncovering data insights and for decision making.
By considering the key areas and evaluating them based on the factors stated above, you can successfully select the right data storage for your enterprise’s business and operational needs.
Backend Technology Interview Questions
C Programming Language Interview Questions | PHP Interview Questions | .NET Core Interview Questions | NumPy Interview Questions | API Interview Questions | FastAPI Python Web Framework | Java Exception Handling Interview Questions | OOPs Interview Questions and Answers | Java Collections Interview Questions | System Design Interview Questions | Data Structure Concepts | Node.js Interview Questions | Django Interview Questions | React Interview Questions | Microservices Interview Questions | Key Backend Development Skills | Data Science Interview Questions | Python Interview Questions | Java Spring Framework Interview Questions | Spring Boot Interview Questions.
Frontend Technology Interview Questions
HTML Interview Questions | Angular Interview Questions | JavaScript Interview Questions | CSS Interview Questions
Database Interview Questions
SQL Interview Questions | PostgreSQL Interview Questions | MongoDB Interview Questions | MySQL Interview Questions | DBMS Interview Questions
Cloud Interview Questions
AWS Lambda Interview Questions | Azure Interview Questions | Cloud Computing Interview Questions | AWS Interview Questions
Quality Assurance Interview Questions
Moving from Manual Testing to Automated Testing | Selenium Interview Questions | Automation Testing Interview Questions
DevOps and Cyber Security Interview Questions
DevOps Interview Questions | How to Prevent Cyber Security Attacks | Guide to Ethical Hacking | Network Security Interview Questions
Design Product Interview Questions
Product Manager Interview Questions | UX Designer Interview Questions
Interview Preparation Tips
Strength and Weakness Interview Questions | I Accepted a Job Offer But Got Another Interview | Preparation Tips For the Virtual Technical Interview | 7 Tips to Improve Your GitHub Profile to Land a Job | Software Engineer Career Opportunities in Singapore | What can you expect during a whiteboard interview | How To Write A Resignation Letter | Recommendation Letter Templates and Tips.
Quick Links
Practice Skills | Best Tech Recruitment Agency in Singapore, India | Graduate Hiring | HackerTrail Litmus | Scout - Sourcing Top Tech Talent in ONE Minute | About HackerTrail | Careers | Job Openings.


