

OOPs Interview Questions and Answers 2023

Object Oriented Programming (also known as OOPs) is a programming style that is based on objects instead of just functions and procedures. Hence, it works on the principles of abstraction, encapsulation, polymorphism, and inheritance. It is used by software developers and programmes in various roles and industries, in areas such as software, web, mobile application, and game development, as well as data science.
With OOPs becoming an increasingly in-demand skill by companies, interviews for positions requiring OOPs have become more challenging and competitive. In order to help jobseekers be best prepared for their technical interviews, we have prepared a comprehensive guide covering the most frequently asked questions and answers on OOPs.
Regardless of whether you have 10 weeks or 10 years of experience with OOPs, this guide provides common OOPs interview questions and answers at the Beginner, Intermediate, Advanced levels and Java OOPs Concepts.
Table of Contents
Basic OOPs Interview Questions and Answers
1. Name some OOPs languages.
- Java
- C++
- C#
- Javascript
- Python
- PHP
2. What is Structured Programming?
Structured Programming is a programming paradigm which is considered as a predecessor to Object Oriented Programming. Programs are constructed using a set of modules or functions.It is difficult to reuse the code in structured programming. This paradigm provides less flexibility and abstraction. PASCAL, C are some of the languages that are based on the structured programming paradigm.
3. List down some of the main features of OOPS.
- Classes
- Objects
- Inheritance
- Encapsulation
- Abstraction
- Polymorphism
4. What is a class?
A class is a user-defined prototype that consists of a number of variables, attributes and functions. It has the blueprint for the objects. It does not consume memory. One can create many objects to a class.
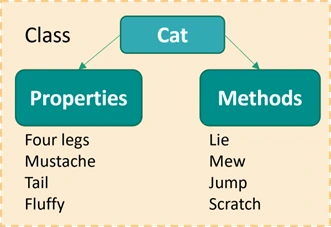
Image Credit: bzfar.org
5. What is an object?
An object is an instance of a class. In the real-world, the object is an entity based on the class blueprint, to which an user interacts. The object, unlike class, consumes memory. It has attributes and behaviors.
6. Provide a real-life example to explain class and object.
To understand the concept of class and object, we can take cars as an example. The class is compared to the blueprint of a car, and object as an individual car. Every individual car has its own attributes based on state and behavior like name, color, weight, speed, number of seats. This is the same as the object that has its own attributes and behavior.
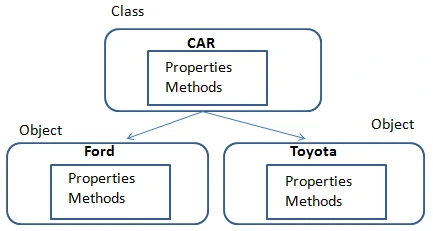
Image Credit: net-informations.com
7. When is the ‘this’ keyword used in OOPs?
The 'this' keyword is used to refer to the current object of a class. This points to the current object, differentiating the global object from a current one.
8. What are access modifiers in OOPs?
Access modifiers in OOP are keywords which are used to set the accessibility of classes, methods, and other members. The access modifiers determine the scope of the method or variables that can be accessed from other objects or classes.
Private, Protected, Public are different types of access modifiers in OOPs.
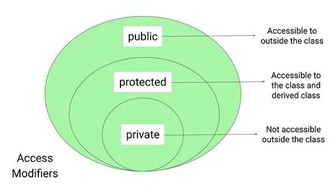
Image Credit: cdn-images-1.medium.com
9. What is Encapsulation in OOPs?
Encapsulation is the process of putting all the necessary data members and methods of a program together for certain tasks into a single unit and the data which are not necessary for a normal user are hidden. The data specified in one class can be hidden from other classes. This can be visualized as putting everything that is necessary together, binding it all, putting that into a capsule, and the encapsulated one is presented to the user.
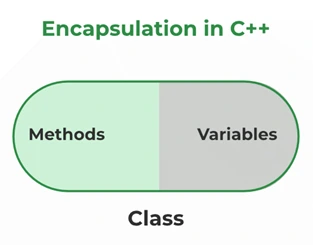
Image Credit: media.geeksforgeeks.org
10. What is Abstraction in OOPs?
Abstraction hides unnecessary details, and shows only the ones which are necessary. Only the important information is shown to the user and the implementation details are hidden. For example, all the wires connected inside a car are hidden from the consumer and show only the necessary details like steering wheel, brakes.
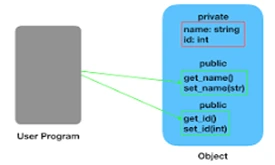
Image Credit: journaldev.nyc3.digitaloceanspaces.com
11. What is Polymorphism in OOPs?
Polymorphism is a combination of 'poly' and 'morph', which means 'many shapes'. Polymorphism refers to certain entities existing in multiple forms. This is a process in which data, method or object behaves and acts differently under different circumstances.
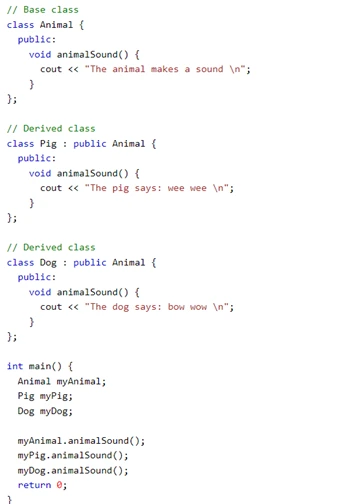
Image Credit: w3schools.com
12. What is Inheritance in OOPs?
The term 'Inheritance' means receiving certain behaviors from a parent to a child. Inheritance is the mechanism which allows classes to inherit properties from other classes. The child class or the derived class inherits the public and protected properties and methods of the parent class, along with its own (child’s) properties and methods. The parent class is also called the base class.
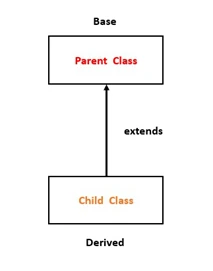
Image Credit: media.geeksforgeeks.org
13. How to call the base class method without creating an instance?
A base class method can be called without creating an instance in the following cases.
- If the method is static
- Calling the inherited method inside a derived class
- Calling the method using the base keyword from the sub-classes
14. What are the limitations of OOPS?
- Requires good amount of planning
- Consumes large amount of memory
- Takes lot of effort to develop the programs
- Takes more time to solve problems
- Needs effort, time and skill to master the paradigm
- Without proper documentation, the code is difficult to understand
Intermediate OOPs Interview Questions and Answers
15. What is an interface in OOPs?
An interface, which is not a class, is used to enforce properties on an object (class). The syntax of an interface looks similar to class definition. A list of functions are inside the {}. Unlike class, interface doesn't declare any variables. Objects cannot be created using an interface. In interface, as all the functions inside an interface are public by definition, keyword 'public' is not used.
For example, there are two classes - lion class and dog class. These classes must have 'eat_food()' action, despite how each animal 'eats food', is the domain of the interface.
package
{
public interface Animal
{
// NO data VARIABLES are allowed in an interface
// only function PROTOTYPES
/**
* Comments...
* Anything that wants to be a "Animal" must, implement this function
*/
function eat_food() : void;
}
}
16. What are the types of inheritance? Explain each type briefly.
- Single Inheritance: Child class derived directly from the base class
- Multiple Inheritance: Child class derived from multiple base classes
- Multilevel Inheritance: Child class derived from the base class which is derived from another base class
- Hierarchical Inheritance: Multiple child classes derived from a single base class
- Hybrid Inheritance: Multiple inheritance types happening among parent and child classes
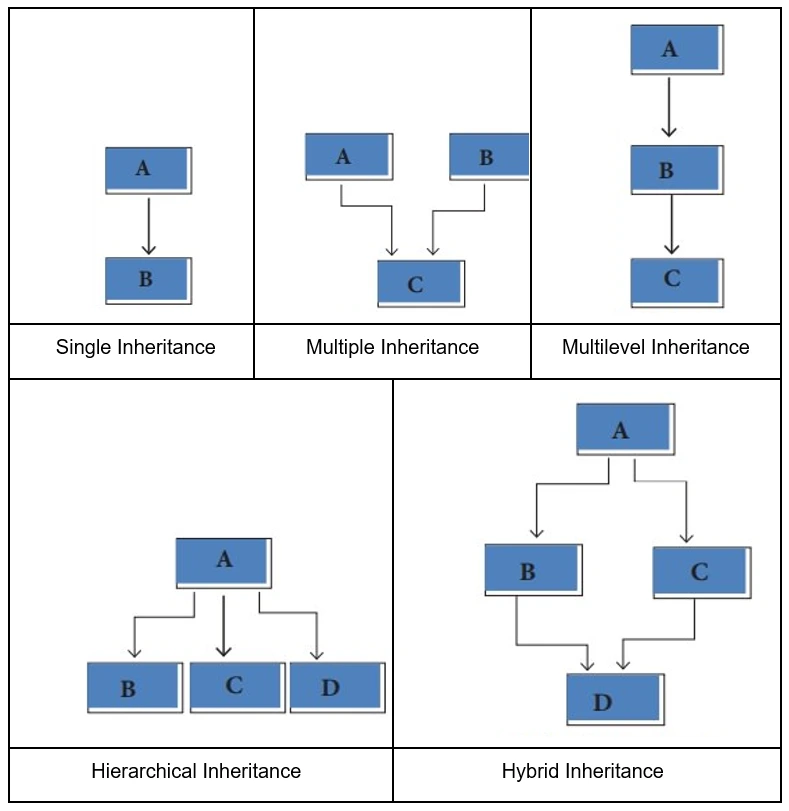
Image Credit: img.brainkart.com
17. What are the limitations of inheritance?
- For the program that involves inheritance, it takes more time to execute as it keeps going from one class to another. The multiple classes increase the execution time.
- As the parent class and the child class are linked, one has to make changes in both classes carefully. Nested changes need to be done in the tightly coupled parent and child classes.
- Inheritance, which is complex to implement, if implemented incorrectly may produce unexpected/incorrect errors.
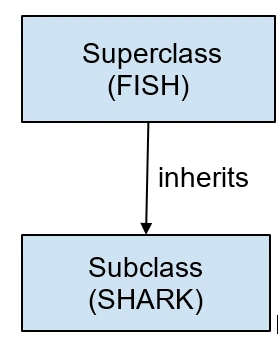
18. What is a superclass? What is a subclass?
Superclass: This is a part of Inheritance in OOPs. It is also called the base class or parent class. This class acts as parent and allows subclasses or child classes to inherit from it.
Subclass: This is a child class which inherits from another class: a superclass or a parent class. For example, the class Shark is a subclass of the superclass Fish.
19. What are method overloading and method overriding?
Method overloading:
Two or more methods can have the same name. But those methods should have different parameters, different numbers of parameters, different types. These are overloaded methods and this feature is called method overloading.
int add(int p, int q) {
return p+q;
}
double add(double p, double q) {
return p+q;
}
int add(int p, int q, int r) {
return p+q+r;
}
In this example, add() has different parameters and different types.
Method overriding:
This allows a child class to provide a specific implementation of a method which is already provided by one of its parent classes.
If a method with the same method signature is presented in both child and parent class is known as method overriding.
class Base {
public: void show() {
cout << "I am the Parent";
}
}
class Derived: public Base {
public: void show() {
cout << "I am the Child";
}
}
In this example, void show() is overridden in the child class.
20. Compare static polymorphism and dynamic polymorphism.
| STATIC POLYMORPHISM | DYNAMIC POLYMORPHISM |
| Occurs during Compile time | Occurs during Run time |
| Collects the information to call a method during compile time | Binding of the object to the function call happens at the runtime, when the object is instantiated. |
| Example: Method overloading | Example: Method overriding |
21. What is the difference between multiple and multilevel inheritances?
Multiple inheritance:
A child class inherits from more than one parent class. There is one child class and multiple parent classes.
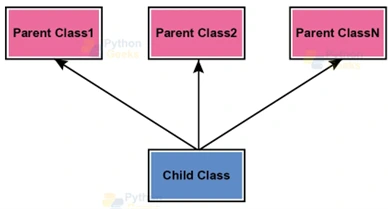
Image Credit: pythongeeks.org
Multilevel inheritance:
A child class inherits from a parent class, and that parent class is a child class to another parent class. A child class inherits from another derived class.
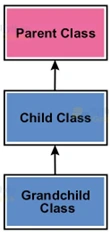
Image Credit: pythongeeks.org
22. What is an abstract class?
Abstract Class is a type of class that defines one or more abstract methods. It is a class which contains at least one pure virtual function A normal class cannot have abstract methods. The abstract class can have abstract methods, but an object cannot be created from it. An abstract class cannot be instantiated.
// Abstract class
class B
{
public:
virtual void show() = 0;
}
23. When is the 'virtual' keyword used?
The 'virtual' keyword is used to create a virtual function. The virtual function is declared in the parent class and redefined by a child class. A derived class can redefine the virtual function, when a class containing a virtual function is inherited. The virtual function ensures that the right function is called for an object, irrespective of the nature of the reference used for the call. Virtual function achieves Runtime polymorphism.
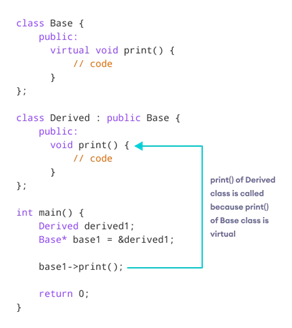
Image Credit: cdn.programiz.com
24. What are pure virtual functions?
Virtual and pure virtual functions are the concepts of Run-time polymorphism. The declaration of both functions remains unchanged throughout the program. These can't be global or static.
As we know that the Virtual function is declared within a base class and is redefined/overridden by a derived class. In pure virtual function, which is also an abstract function, there is no implementation, but there is only declaration by assigning 0.
// Abstract class
class B
{
Public:
//pure virtual function as the ‘0’ is assigned
virtual void show() = 0;
}
25. What is early and late binding?
When values are assigned to variables during design time, this is called as early binding. Unlike the Early binding, when the values are assigned to variables during run time, it is late binding.
26. Briefly explain data hiding and data binding.
Data hiding and data binding are two ways to define encapsulation.
- Data hiding: The process of hiding unwanted, unnecessary information and showing only the necessary information, such as restricting access to a member, is encapsulation.
- Data binding: The process of binding the data members and the methods together in a capsule as a class, is encapsulation.
27. ‘Classes do not occupy memory.’ Justify the statement.
Class is a blueprint, based on which individual objects are created. As the class is just a template, it does not occupy any memory. The object occupies memory.
28. ‘Constructor can not be declared private.’ Is it a True or a False statement?
False. A constructor can be declared as private.
29. List a few advantages of OOPs.
- Code reusability - The class once written, can be used many times by creating the object for the class.
- Data redundancy - Common class definitions for similar functionalities can be written and can be inherited if similar functionality is required in multiple classes.
- Code maintenance - The codes that are existing can be easily maintained and can be modified by making small changes in the existing ones.
- Security – Using data hiding and abstraction, the data available to the user can be filtered and limited.
- Planning - As extensive design and planning is done for the OOPs, the results are better and the errors are minimal.
Advanced OOPs Interview Questions and Answers
30. What are the levels of data abstraction?
There are three levels of data abstraction:
- Physical Level: This lowest level of data abstraction shows how the data is stored in memory.
- Logical Level: This level has the data stored in the database in the form of tables, and stores the relationship among the data entities.
- View Level: This is the highest level of data abstraction. The database is visible and available to the user.
| View Level (Highest Level) | Database available for User |
| Logical Level | How the data stored in the database |
| Physical Level (Lowest Level) | How the data is stored in memory |
31. Explain the constructor and the destructor.
- Constructor: This is a special type of method whose name is the same as the class. This is a block of code which is used to initialize objects.
- Destructor: This is also a special type of method. But, unlike constructors which specify space for them, the destructors free up the resources and the memory occupied by an object. When an object is destroyed, the destructors are automatically invoked.
class Disp
{
int a;
public:
// constructor, with the same name as class
Disp()
{
// CODE
cout<<"This is constructor";
}
// destructor
~Disp()
{
//CODE
cout<<"This is destructor"
}
};
32. What are the types of constructors?
- Private Constructor
- Default Constructor
- Copy Constructor
- Static Constructor
- Parameterized Constructor
33. What is a copy constructor?
Copy Constructor is a type of constructor and its purpose is to copy an object to another by cloning the object, along with its value.
className(const className &object_name)There are two types of copy constructors:
- User-Defined Copy Constructor
- Default Copy Constructor - If the constructor is not specified by the User, then the default copy constructor is created.
34. What is a private constructor?
A private constructor is a special instance constructor, which restricts the instantiation of a class. When a constructor is declared private, an object for the class cannot be created. The private constructor does allow object creation within the current scope, but not allow object creation outside the class.
35. Explain exception handling.
Exception is a message/notification that interrupts the usual execution of a program when there is an issue. Exceptions transfer the error to the exception handler to solve it. The exceptional circumstances are not necessarily to be an error all the time. The exception handling mechanism manages errors, and handles exceptional circumstances. The handler throws the error and catches that later to resolve the issue.
36. What is the importance of garbage collection?
Garbage collection is a form of memory management. It is a memory recovery feature which free up memory space and reclaim it, which was allocated to objects which are currently not in use or no longer needed by the program. Most programming languages have built-in garbage collection and some other languages add garbage collection through libraries.
37. Compare abstraction with encapsulation.
| Abstraction | Encapsulation |
| Shows useful data which are necessary | Wraps code and data for required information |
| Hides unwanted information | Hides and protects data from inside and outside |
| Solves problems at the design or interface level | Solves problems at the implementation level |
| Implemented by abstract classes and interfaces | Implemented using access modifiers: public, private, and protected |
| Objects that perform abstraction can encapsulate | Objects that perform encapsulation cannot perform abstraction |
38. What are the operators that cannot be overloaded?
- Dot or Member access operator – ( . )
- Scope resolution operator – ( :: )
- Ternary operator – ( ? : )
- Pointer to member operator – ( .* )
- Object size operator – (sizeof)
- Object type operator – (typeid)
39. What is a structure?
A structure is a collection of elements of data types. Structure provides flexibility to store diverse data in a single functional unit. It does not support inheritance and data abstraction. The structure is saved in stack memory. An instance of a structure is a structure variable. The keyword struct defines a structure.
struct student
{
//members of the struct
string name;
int rollno;
float percent;
}
40. Explain the different types of access modifiers.
| Public | Private | Protected | Default |
|
Access level is within and outside the package, within and outside the class. Can be accessed from everywhere. |
Access level is within the class only. Can be accessed from outside the class. |
Access level is within the package, through the child class, and outside the package. Cannot be accessed from outside the package, if the child class is not defined. |
Access level is only within the package, and cannot be accessed from outside the package. If the access level is not specified, it will be the default. |
41. Name the access modifiers for methods inside an interface.
The methods are public by default, inside an interface. Other than the ‘public’ modifier, no other modifier can be specified.
42. What is Coupling in OOP, and why is it helpful?
In OOPs, the coupling is the degree of dependency between the components. There are two types of coupling.
- Tight Coupling: The highly dependent components are tightly coupled
- Loose Coupling: In this, the dependency between components is low. Loose coupling is preferred as it increases the maintainability of code and provides reusability of code.
43. What are the final variables?
The ‘final’ keyword means the variable or method cannot be changed in the future and it is final. A reference variable which is marked as final, receives one explicit initialization only, and is unchangeable in its object reference. Though the reference cannot be changed, the data included in the object and the object’s state can be altered.
class B {
public static void main () {
// variable declared as final, will not change
final double PI = 3.14;
//code
}
}
44. Compare exceptions and errors.
| Exception | Error |
| recovered by using try-catch blocks | cannot be recovered. |
| occur at compile time or run time | occurs at run time |
| caused by the application | caused by the environment in which the application is running. |
OOPs Concepts in Java Interview Questions and Answers
45. What is Object-Oriented Programming?
It is a programming hypothesis that works on the principles of abstraction, inheritance, encapsulation, and polymorphism. The basic idea of Object-Oriented Programming is to produce objects, re-use them across the program, and utilize these objects to acquire results. Moreover, OOP relies on these objects, instead of functions, to bind data and operations together.
46. What are the core OOPs concepts in Java?
- Class: A cluster of similar logical entities in a program.
- Object: It is an instance of a class. A class can have multiple instances.
- Inheritance: Inheritance refers to an Object-Oriented Programming concept in which one object acquires the characteristics of the object of another class.
- Polymorphism: The capability of a variable, object, or function to take on multiple forms.
- Abstraction: Abstraction in Java is a concept of representing vital features of a class or method without including their background information.
- Encapsulation: An OOPs concept in Java that packages data and code together.
47. What are the advantages of Object-Oriented Programming features in Java?
The Java OOPs concepts offer various benefits that other procedural programming like C, Pascal, etc. do not offer.
- Data is encapsulated with procedures in the class to secure the data from unexpected modifications.
- Java OOPs concepts encourage reusability and avoid redundancy by using the features of an existing class in a new class. For example, by using Multilevel Inheritance in Java, you can easily use features of class C, via class B into class A.
- Objects use a message-passing technique for communication thereby creating the interface descriptions easier for external systems.
- Reduces complexity through Inheritance which makes it the preferred approach for developing complex applications.
- Uses a bottom-up approach that makes it easy to upgrade from small to large systems.
- Code written using OOPs concepts in Java is easy to maintain.
- Helps in building efficient applications with simpler development processes.
48. What is Inheritance in Java?
Inheritance in Java is a process in which one class attains the features i.e. variables and procedures, of some other class.
In Object-Oriented Programming in Java, inheritance provides the concept of reusability of code within an application. Here, each subclass defines only the features that are unique to it, and the rest of the features it can acquire from the parent class. Therefore, inheritance creates a hierarchy of classes thereby making them easier to maintain.
Furthermore, the class which derives certain properties of another class is known as a subclass, derived class, or child class. Similarly, the class from whom the subclass inherits its properties is known as a superclass, base class, or parent class.
The subclass uses the keyword ‘extends’ to inherit a superclass.
The syntax for implementing inheritance in Java:
class SuperClass {
.....
.....
}
class SubClass extends SuperClass {
.....
.....
}
49. How many types of inheritance are there in Object-Oriented Programming? Which inheritance types does Java support?
There are six supported types of inheritance in OOPs, which are Single Inheritance, Multi-level Inheritance, Multiple Inheritance, Multipath Inheritance, Hierarchical Inheritance, and Hybrid Inheritance.
However, there are three types of inheritance Java supports:
- Single Inheritance- A child class inherits a single parent class. For instance, ClassY inherits ClassX.
- Multilevel Inheritance- In Multilevel Inheritance in Java, a child class inherits a parent class that has inherited another class. For example, Class Z inherits ClassY. ClassY inherits ClassZ
- Hierarchical Inheritance- With this type of inheritance, Java enables multiple child classes to inherit a single parent class. i.e. ClassY and ClassZ inherit ClassX.
50. Why Multiple Inheritance is not supported in Java?
Multiple Inheritance is a concept where a child class can inherit from more than one parent class. The reason why Multiple Inheritance is not supported in Java is that it can lead to ambiguity. For instance, if two or more parent classes that a child extends have a common method, then the compiler will be unable to decide which method to use.
Like multiple inheritance in Java, we cannot implement Hybrid Inheritance in Java too. As it is a combination of multiple and single inheritance, Hybrid Inheritance in Java implementation through classes will result in ambiguity as well.
Hence, to enforce simplicity, there is no provision of hybrid and Multiple Inheritance in Java.
51. Are there any limitations of Inheritance?
Inheritance in Java is a powerful concept to enable reusability. However, it too comes with a few limitations:
- Firstly, there is an increase in program execution time due to constant to and fro between parent and child classes.
- Next, Inheritance leads to tight coupling between the superclass and the subclass.
- Thirdly, in case of modifications in the program, the developer needs to make changes in both the superclass and the subclass.
- Lastly, it requires careful implementation otherwise, the program would yield incorrect functionality.
52. What are static methods in Java? Can they be used in Inheritance?
In Java, static methods are created using the keyword ‘static’. As these methods are made static, they will be independent of any instances of the class. Also, static methods do not accept values from an instance variable of the object of the class. Instead, method parameters pass all the data to static methods. The computation then takes place on the values passed in the parameter, without any reference to the variables.
Yes, we can inherit static methods in Java. A child class inherits all of the public and protected members of its parent class within the same package. Therefore, it will inherit static methods as well. Though the child class can use the inherited static methods as is, it cannot override them.
53. What is Encapsulation in Java?
Encapsulation in Java refers to wrapping up the data and the methods to access and transform the data into a single entity. If we talk about Encapsulation in Java with examples, the first name to appear will be of the Spring Bean class.
In encapsulation, the variables of a class will be hidden from other classes by declaring them as private. And to modify and view the values of these variables, we have to declare the setter and getter methods. Therefore, encapsulation is also known as data hiding.
As it is easier to understand Encapsulation in Java with examples, here is a simple program for the same:
`/ File name : EncapTest.java /
/* Example taken from TutorialsPoint
public class EncapTest {
private String name;
private String idNum;
private int age;
public int getAge() {
return age;
}
public String getName() {
return name;
}
public String getIdNum() {
return idNum;
}
public void setAge( int newAge) {
age = newAge;
}
public void setName(String newName) {
name = newName;
}
public void setIdNum( String newId) {
idNum = newId;
}
} `
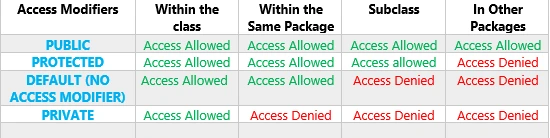
54. What is Access Modifier in Java? What are the different types of Access Modifiers and their scope?
Access Modifiers in Java are specialized keywords with which a user can set the level of accessibility or scope for a class, method, constructor, or variables.
Java uses four types of access modifiers:
- Private- Accessible only from within the class.
- Default- Can be accessed from within the package. No accessibility outside the package.
- Protected- Direct access from inside the package. You can use child class to access from outside the package.
- Public- Can be accessed from anywhere.
The below image succinctly describes the scope of what is an Access Modifier in Java:
55. What are Non-Access Modifiers in Java?
These modifiers help to achieve a lot of miscellaneous programming functionalities in Java.
Overall there are six Non-Access Modifiers in Java:
- Static Modifier: The Static Modifier can create variables and methods that are independent of any instance of a class.
- Final Modifier: A variable declared with the final keyword can be initialized only once. If you declare a variable static and final together, it becomes a constant in Java. Moreover, you cannot override a final method in Java and a final class can’t become a subclass.
- Abstract Modifier: Next is the Abstract Non-Access Modifiers in Javathat declares methods without any implementation. It's the subclass that inherits these methods and defines them. Similarly, you can’t instantiate an abstract class except through a subclass.
- Synchronized Modifier: If we define a method using this modifier, then only a single thread will be able to access the synchronized method.
- Transient Modifier: This modifier tells the Java Virtual Machine to skip a transient variable while serializing the object containing this variable.
- Volatile Modifier: The last Non-Access Modifier in Java is volatile that instructs JVM to ensure that the thread that is accessing the variable should merge its private copy with the master copy in the memory.
56. What is Abstraction in Java?
In Object-oriented programming, the Abstraction definition says "it is a process of hiding the implementation details while providing only the functionality to the user. So the user will know only the essential details about what the object does but not how it does it.
Moreover, the Abstraction Java concept is implemented through interfaces and abstract classes.
57. What is the difference between Abstract class and Interface class?
Abstract Class in Java
- Can inherit either a single class or one abstract class at a time.
- An Abstract Class in Java can extend another Java class.
- Can have both abstract and concrete methods.
- The keyword "abstract" is a must to declare a method as abstract.
- Another difference between Abstract class and Interface class is that the Abstract class method in Java can be protected or public.
- An Abstract Class in Java can have a static, final, or static final variable with any access specifier
Interface in Java
- Can extend multiple interfaces at a time
- Can only extend an interface
- Can have abstract methods only.
- The keyword "abstract" is optional for declaring an abstract method.
- Interface, on the other hand, can use only public abstract methods.
- An interface uses just public static final variables. Such variables are constants.
No, it is not possible to instantiate an Abstract Class in Java. This is because, in Abstraction, Java uses abstract classes that do not have a complete implementation. These classes only act as a template for child classes. To use an empty or partially empty structure of such a class, you need to extend it and define the abstract class methods in Java before using them.
Other Backend Technology Interview Questions and Answers
C Programming Language Interview Questions | PHP Interview Questions | .NET Core Interview Questions | NumPy Interview Questions | API Interview Questions | FastAPI Python Web Framework | Java Exception Handling Interview Questions | Java Collections Interview Questions | System Design Interview Questions | Data Structure Concepts | Node.js Interview Questions | Django Interview Questions | React Interview Questions | Microservices Interview Questions | Key Backend Development Skills | Data Science Interview Questions | Python Interview Questions | Java Spring Framework Interview Questions | Spring Boot Interview Questions.


